Speech waveform synthesis from MFCC sequences with generative adversarial networks论文解读
Mel频率倒谱系数(MFCC)常用于语音识别和说话人身份确认,然而MFCC还原为语音是一个困难的过程。我们前面在一些GAN实现声音到图像转换的论文中经常看到, 图像转换过来的往往是语音信号的MFCC图,由MFCC如何还原回语音对于实现完整的模态转换意义是很大的。 Speech waveform synthesis from MFCC sequences with generative adversarial networks 实现了由MFCC还原出高质量语音信号,实验演示可在这里查看(需要翻墙)。
论文引入
MFCC:Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)的缩写。Mel频率是基于人耳听觉特性提出来的,它与Hz频率成非线性对应关系。 Mel频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征,MFCC已经广泛地应用在语音识别领域(ASR)和说话人验证(ASV)。 由于MFCC是针对这些任务而设计的,因此它们的使用会丢弃许多在识别任务中被认为无关的信号细节。MFCC在识别和分类任务中的成功部分归因于这种有损压缩, 其近似于听觉中的感知特性。具体而言,MFCC将频谱包络与精细结构分开,并使用基于听觉尺度的非线性频率分辨率。
MFCC来重建语音信号是很意义的,例如,在ASR中识别错误背后的原因或转录错误的分析效应可能会从MFCC转换为语音中获益;此外,利用MFCC的最先进的ASR和ASV系统可以产生新颖的变换技术, 例如基于说话者验证模型的非并行语音转换。还有就是在做跨模态生成上,图像和语音间的转换,往往图像转换到MFCC就结束了,这对于实现端到端的转换还差一步, 所以由MFCC到语音的生成是很有必要的。
MFCC中包含的光谱信息可以被视为包络,仅给出该包络对于语音的合成是不够的,还必须从MFCC恢复语音的基本频率(F0)和发声信息。由MFCC恢复语音的基本频率(F0)和发声信息已经有一定的进展, 在GMM-HMM框架中进行了研究,其中F0和声音是通过与MFCC的GMM联合分布成功预测的。但是随着深度学习的发展,RNN展现了很好的实现效果。
MFCC转换为语音的方法已经有一定的发展了,其中相对简单的是最小相位在谐波频率处采样恢复频谱幅度,在时域中,这对应于激励具有脉冲序列的最小相位包络滤波器, 该过程不包括浊音语音合成中的任何非周期性,并且在自然语音的激励(即,语音流)中失去混合相位特性。近期,已经提出基于神经网络的激励模型来为统计参数语音合成 (SPSS)中的源滤波器声编码生成更逼真的激励波形。以前的工作使用各种声学特征(例如F0,声道和声门源包络参数和谐波噪声比),并训练神经网络将它们映射到音高锁定声门激励波形。 不幸的是,由于时域中的逐点回归,这种类型的激励模型受到限制,这导致平滑和高频损失。为了克服这个问题,最近提出了一种基于生成对抗网络(GAN)的激励模型。 但是GAN的弊病也是存在的,训练不稳定和多样性不足的问题。
基于以上的这些问题,这篇论文提出三个主要贡献来研究MFCC的语音合成:
- 从MFCC高精度地预测F0,优化SPSS预测的F0模型。
- 提出了一个激励模型,它将MFCC和F0映射到使用MFCC衍生的信号通过反向滤波语音获得的激励波形。
- 引入了一个改进的残差GAN噪声模型,用于生成在最小二乘激励模型中丢失的高频随机分量。
合成语音模型
我们先一起来看看论文中使用的模型框架:
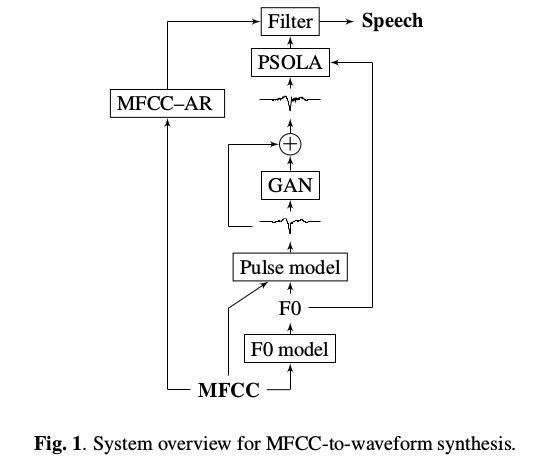
整个模型从下向上看,首先由MFCC通过F0预测模型恢复出语音的基本频率F0,F0和发声信息经过激励脉冲模型得到平滑的脉冲,送入残差GAN噪声模型生成带有高频分量的信号, 为了产生连续的激励信号,所产生的脉冲以节距同步的方式连接,由产生的F0确定。最后得到的信号和MFCC重构的包络信号经过滤波器得到语音波形从而还原出语音。 接下来将对分模块做进一步的描述。
F0预测模型
F0模型将一系列MFCC作为输入,并从中生成相应的F0轨道和发声信息,整体实现是在RNN基础上完成的,利用自回归输出反馈链路和分层softmax来预测来自输入的量化F0类。 F0范围被线性量化为255个二进制位,并且一个附加类被保留用于清音语音。
MFCC重构包络
整体上采用伪逆的思路重构包络,过程相当于由包络得到MFCC的逆过程,与插值方法相比观察到伪逆在实践中表现良好并且给出具有更尖锐的共振峰结构的包络。
激励脉冲模型
之前的方法使用将声学特征映射到声门激发脉冲的神经网络,近期提出了一种用于SPSS中声门发声的激励模型。首先通过声门反向滤波获得声门源信号(通过声带的差分体积流量), 之后通过以间距标记来提取激励脉冲,对两个音高周期段进行余弦加窗,并且将脉冲填充到固定长度。最后,在训练之前,每个声学特征帧与最近间距标记处的脉冲相关联。 在所有基于源滤波器模型的语音编码中通常可以采用类似的框架,其中滤波器允许对语音信号进行反向滤波。
对于模型架构,在输入端使用门控循环单元(GRU)层,因为循环网络对于编码声学序列信息非常有用,其中循环网络略微改善了TTS应用中的激励模型性能。 此外,在靠近波形水平工作时,已经发现卷积层很方便。在给定输入的情况下,该模型将不可避免地向条件平均值回归,这导致平滑的波形和高频损失。 可由下图说明:
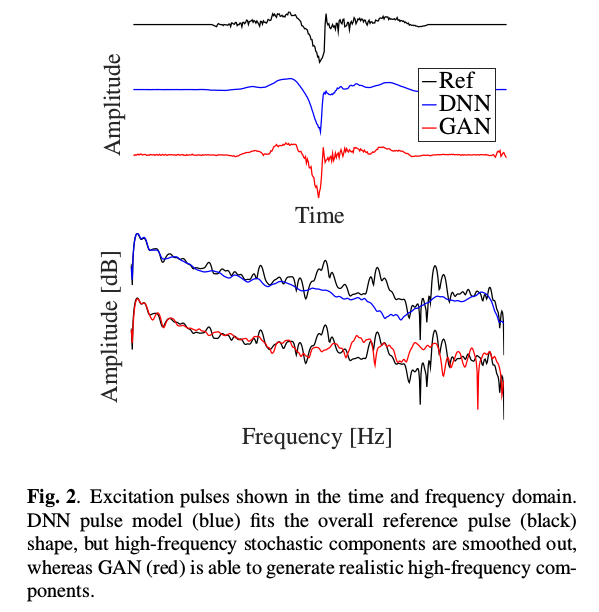
残差GAN模型
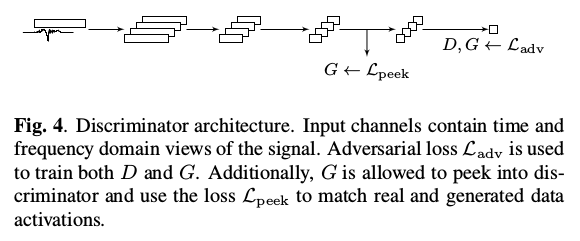
GAN以平滑生成的脉冲为输入,由此生成附加的残余高频分量。将LS-GAN与基于GAN的相似性度量学习相结合优化网络。发生器和鉴别器结构如下图所示:
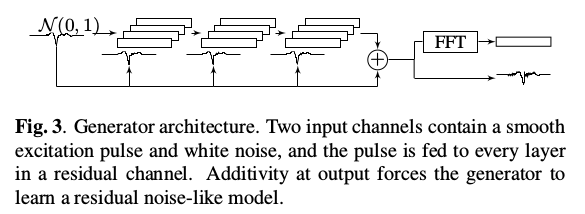
由上图所示,发生器的输入是平滑的脉冲信号和高斯白噪声信号,平滑波形进一步馈入每层作为附加残余信道,输入和卷积层输出的显式可加性确保生成类似于残余噪声。 最后,FFT幅度层允许训练过程同时看到时域和频域中的输出,并且误差信号可以通过两个路径传播。
鉴别器输入通道是真实和生成时域和频域的信号,用于判断输入样本的真假。允许生成器在层L处查看鉴别器激活,并使用隐含的相似性度量来将生成的数据小批量直接与对应的实际数据匹配。 即:
\[L_{peek}(G) = \frac{1}{2}E_{x,x'}[(D_L(x) - D_L(x'))^2]\]其余部分优化过程和普通的GAN相似。
实验
数据集上使用现有的SPSS训练数据训练了两个特定于扬声器的系统。两位演讲者都是专业的英国英语配音演员,“Nick”(男性)数据集包含2542个话语, 总计1.8小时,“Jenny”(女性)数据集包含4080个话语,大约是4个小时。随机选择一组100个话语用于测试两个扬声器,其余用于训练。整个研究中使用16kHz的采样率。
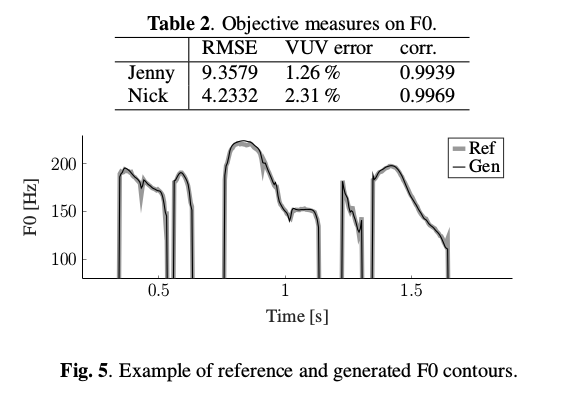
F0模型性能通过浊音F0的均方根误差(RMSE),发声决策误差百分比(VUV误差)以及参考和生成的F0值之间的相关系数来测量,下表是实验测试结果:
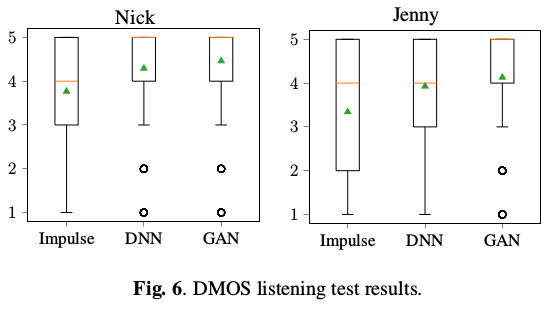
在DMOS听力测试中比较了三个系统。所有系统都使用从MFCC重建的全极点包络,以及由F0模型生成的F0和发声信息。在所有系统中,白噪声用于清音激发。 系统“Impulse”使用简单的脉冲序列进行浊音激励,系统“DNN”使用由DNN激励模型生成的平滑激励脉冲,“GAN”另外使用残差GAN噪声模型。 使用自然语音信号作为参考,并且要求听众将合成测试样品的降解从1(非常烦人)降至5(听不见)。该测试是在CrowdFlower人群采购平台上进行的, 该平台由英语国家提供,并且EF英语水平指数排名前四位。每个测试案例由50名听众在15个测试集发音上进行评估。评估分数如下图所示,模式值用水平线标记, 平均值用三角形标记。
总结
论文提出了一种MFCC语音重建方法。使用在量化F0值上运行的自回归RNN,可以从具有高精度的MFCC生成F0轮廓。通过MFCC计算的最小二乘反演来恢复MFCC中的谱包络信息, 并且针对MFCC衍生的滤波器训练DNN激励模型。另外,提出了一种残差GAN噪声模型,可用于生成逼真的随机信号分量,而无需对非周期性或类似特征进行显式参数化。 听力测试表明,已经从MFCC导出的包络和脉冲序列激励中获得了合理质量的语音重构。通过提出的DNN激励模型和GAN噪声模型获得了进一步的改进, 从而实现了MFCC的高质量语音合成。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







