SAGAN代码简单实现
SAGAN的论文(Self-Attention GAN)解读我们之前的博客中已经写过了,今天我们来简单实现一下SAGAN的实验。 本实验的基础是在我的github上传的tensorflow-GANs的基础上完成的,所以只是简单的复刻, 旨在说明如何实现并不强调调参和具体细节,所以代码只演示mnist数据集下的实验结果。
SAGAN已有代码整理
目前SAGAN已经公布了pytorch源码,tensorflow版本的也已经有人整理出来了,详细地址在下面。
今天我的目的就是在我之前写的博客GAN代码的搭建系列的基础上加上Self-Attention部分即可, 所以在框架基础不变的情况下完成SAGAN的功能。
SAGAN核心框架回顾
SAGAN的创新点仅仅在于加入了Self-Attention的部分,这一部分可以用下图表示:
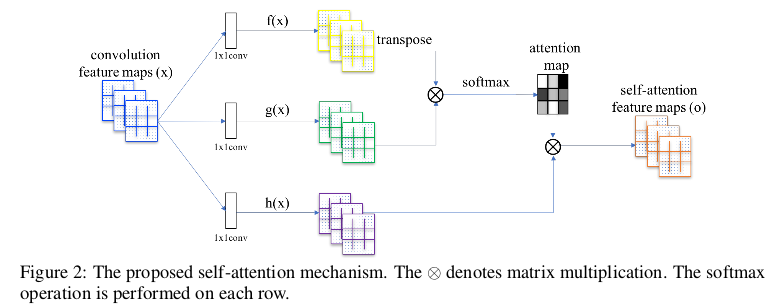
整体的思路就是,提取特征图\(x\)通过\(1 \times 1\)的卷积网络变换成三个\(f(x),g(x),h(x)\)其中为了实现全局注意机制,这里的\(f(x),g(x)\) 的channel要小一点,\(f(x),g(x)\)通过矩阵相乘得到Attention map。为了保证输出的channel不变,这里还需要再与\(h(x)\)做矩阵相乘从而作为考虑了全局注意机制的输出。
阐述完Sel-Attention的整体思路,我们就可以用代码去实现。
SAGAN代码实现
首先我们需要定义attention层的函数,然后在GAN的内部直接调用即可,我们假设提取到的feature map的channel为128的时候。
def attention(self, x, is_training=True, scope='attention', reuse=False):
with tf.variable_scope(scope, reuse=reuse):
f = tf.nn.relu(bn(conv2d(x, 16, 4, 4, 1, 1, name='f_conv'), is_training=is_training, scope='f_bn'))
g = tf.nn.relu(bn(conv2d(x, 16, 4, 4, 1, 1, name='g_conv'), is_training=is_training, scope='g_bn'))
h = tf.nn.relu(bn(conv2d(x, 128, 4, 4, 1, 1, name='h_conv'), is_training=is_training, scope='h_bn'))
s = tf.matmul(hw_flatten(g), hw_flatten(f), transpose_b=True) # [bs, N, N]
beta = tf.nn.softmax(s, axis=-1) # attention map
o = tf.matmul(beta, hw_flatten(h)) # [bs, N, C]
gamma = tf.get_variable("gamma", [1], initializer=tf.constant_initializer(0.0))
o = tf.reshape(o, shape=x.shape) # [bs, h, w, C]
x = gamma * o + x
return x
我们定义\(f(x),g(x)\)的channel为16,也就是输入的feature map的channel数的\(\frac{1}{8}\),这和源码给出的思想是一样的,我们只做保留。
定义完Attention层之后,我们就可以在GAN的程序中直接使用了,其实实现起来很简单,只需要在Generator和Discriminator相应的特征加入Attention即可。
def generator(self, z, is_training=True, reuse=False):
with tf.variable_scope("generator", reuse=reuse):
net = tf.nn.relu(bn(linear(z, 1024, scope='g_fc1'), is_training=is_training, scope='g_bn1'))
net = tf.nn.relu(bn(linear(net, 128 * 7 * 7, scope='g_fc2'), is_training=is_training, scope='g_bn2'))
net = tf.reshape(net, [self.batch_size, 7, 7, 128])
net = self.attention(net, scope="attention", reuse=reuse)
net = tf.nn.relu(
bn(deconv2d(net, [self.batch_size, 14, 14, 64], 4, 4, 2, 2, name='g_dc3'), is_training=is_training,
scope='g_bn3'))
out = tf.nn.sigmoid(deconv2d(net, [self.batch_size, 28, 28, 1], 4, 4, 2, 2, name='g_dc4'))
return out
def discriminator(self, x, is_training=True, reuse=False):
with tf.variable_scope("discriminator", reuse=reuse):
net = lrelu(conv2d(x, 64, 4, 4, 2, 2, name='d_conv1'))
net = lrelu(
bn(conv2d(net, 128, 4, 4, 2, 2, name='d_conv2'), is_training=is_training, scope='d_bn2')) # 数据标准化
net = self.attention(net, scope="attention", reuse=reuse)
net = tf.reshape(net, [self.batch_size, -1])
net = lrelu(bn(linear(net, 1024, scope='d_fc4'), is_training=is_training, scope='d_bn4'))
out_logit = linear(net, 1, scope='d_fc5')
out = tf.nn.sigmoid(out_logit)
return out, out_logit, net
其他地方和GAN的基础框架完全一致,这里就不做重复阐述了!
本文的完整代码可点击这里查看。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







