Deep Cross-Modal Audio-Visual Generation论文解读
上篇博客我们写到了CMCGAN论文解读,其实CMCGAN之前就已经有学者利用GAN的思想实现了Audio<–>Visual的转换, 这篇文章是来自罗彻斯特大学的Deep Cross-Modal Audio-Visual Generation.这篇文章无论是理论模型分析, 还是实验验证说明都是上乘之作,今天我们一起来看看这篇论文。
引入
在这篇文章之前是没有学者进行过跨模态之间的相互生成,甚至到现在跨模态之间的相互生成这个领域触碰的学者还是相当少的,这个可以从这几年发表的顶级论文中看的出来。 目前的跨模态的研究还主要是在信息的索引和检索上,然而跨模态的相互生成具有很大的意义。跨模态的相互生成可以进行数据的还原,数据模态的扩充和模态之间的信息分析。 这篇文章开启了一个模态转换生成的先河,文章利用GAN的思想实现了这个转换的跨越。我们为了方便描述以下我们将文章简称为CMAV。
CMAV实现了Audio<–>Visual的转换生成,这个和我们上期说的CMCGAN实现的差不多。仔细研读这两篇论文也可以发现CMCGAN借鉴了很多CMAV的思想, 在这里我就不对两篇文章做实质性比较了,从CMCGAN的论文实现效果上可以看出是好于CMAV的,由于两篇论文的代码没公布我也没对这两篇论文的代码进行复刻所以我也不好界定到底哪一篇更好一点。 不过就实验的充分性上,可能我们今天说的CMAV要更好一点。
CMAV文章具有以下贡献:
1.文章是第一个实现跨模态视听相互生成,并且是第一个在人体感官生成中使用GAN的作品。
2.文章为跨模态GAN提出新的网络结构和对抗训练策略。
3.文章构造了两个数据集,这些数据集将被发布以便在这个新的问题中进行未来的研究,目前这两个数据集也发表了文章。
CMAV模型介绍
这篇论文是第一个实现Audio<–>Visual相互转换生成的文章,这个得益于罗彻斯特大学团队做的Sub-URMP和INIS数据集。一个好的团队可以实现共同领域很大的发展。 我们一起来看看这个利用GAN实现Audio<–>Visual转换的模型结构。
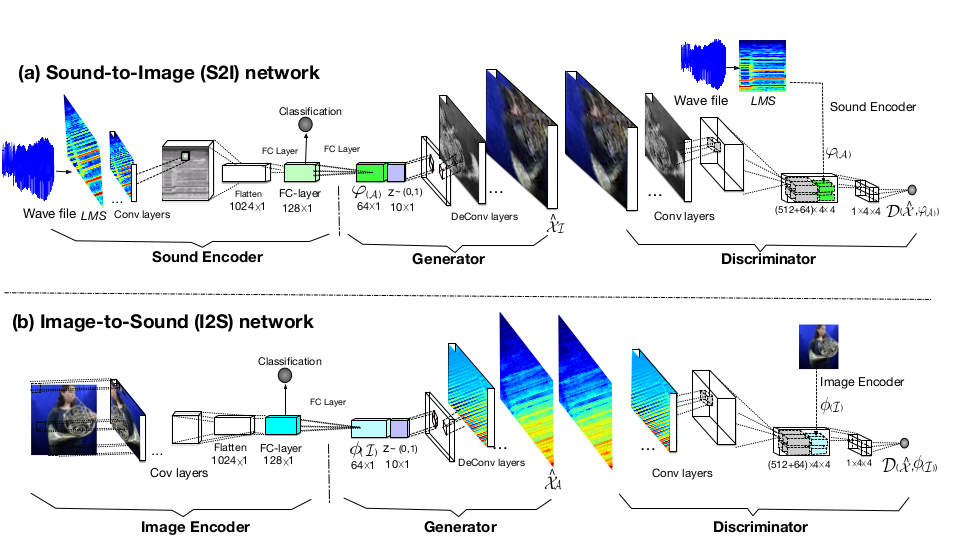
我们可以看到,模型分为两大网络结构,(a)网络是Sound-to-Image,也就是声音到图像的转换生成,其实这个网络是文章的重点,论文很大篇幅在围绕着这个展开, 因为声音在论文中一共使用了13类乐器,但是对应的人物演奏的图片多达上万张,并且每种乐器对应的演奏者在1到5人之间,所以由声音生成图像是需要好好考虑的。 比如萨克斯的声音生成演奏萨克斯的人物图像,我们需要对应不同的人,不同的姿势和不同的乐谱。这个在后续的损失函数里面我们会再次分析。 (b)网络是Image-to-Sound,这个相对就没这么复杂了,就是通过图片去生成对应的声音图谱。
在详细展开之前,我们来简要说明一下本论文对声音的处理。论文一开始对声音的处理也是在不断的尝试,不过大体上都是先将声音转换为对应的声谱图, 论文尝试了很多的转换方法,具体列出来有以下几种:
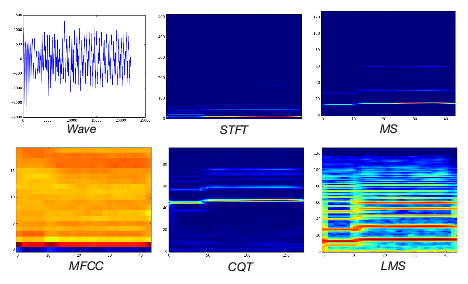
论文通过对比这几种转换后的声音图谱在声音分类器下分类的准确率来确定最终的方案,并且在分类器的设计上通过对比分类器确定网络的结构, 我们看一下各类声音图谱分类准确率:

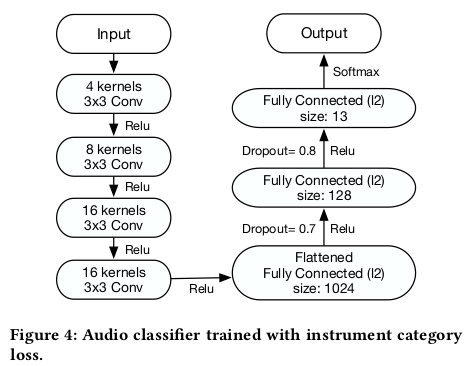
通过对比准确率和较高准确率对应的卷积层数,最终选择了LMS声音图谱和4层卷积层作为声音数据的处理方式,下面是确定下来的声音分类器的网络结构:
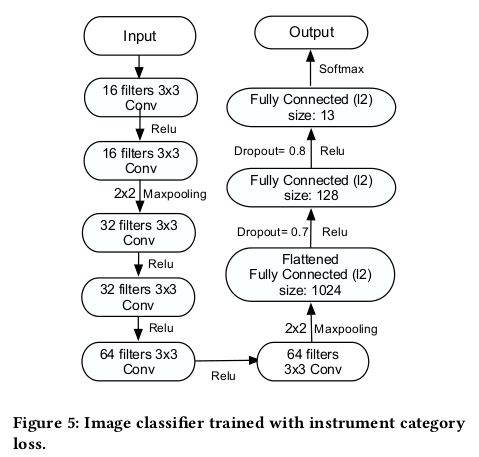
对于图像的分类器,就是将乐器图能正确的分类出是哪一个乐器类别的图片,他的网络结构:
由以上介绍我们一起来分析一下(a)中声音到图像这一路的模型结构,输入声音经过处理到LMS的声音频谱图,经过卷积层,全连接层到128维的特征map,这时候就可以对其进行分类判断了,
再通过一个全连接层到64维的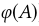 ,加上10维的latent vector z就构成了Generator的输入,
通过反卷积生成乐器图
,加上10维的latent vector z就构成了Generator的输入,
通过反卷积生成乐器图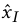 ,这一个过程就是
,这一个过程就是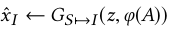 。
此时就已经完成了声音到图像的生成了,当然这个效果肯定特别差,这时候我们就需要优化了,怎么优化呢?这时候判别器Discriminator就起作用了。
S2I的判别器输入是有两个,一个是对应的乐器图像,另一个就是LMS经过Encoder得到的,为啥要这样处理呢?
这就要说道配对的思想了,如果我的生成乐器图和声音配对不上我们认为这是错误的,只有图和声音对上才认为是真的,这个在后面的损失函数的设计上也有所体现。
。
此时就已经完成了声音到图像的生成了,当然这个效果肯定特别差,这时候我们就需要优化了,怎么优化呢?这时候判别器Discriminator就起作用了。
S2I的判别器输入是有两个,一个是对应的乐器图像,另一个就是LMS经过Encoder得到的,为啥要这样处理呢?
这就要说道配对的思想了,如果我的生成乐器图和声音配对不上我们认为这是错误的,只有图和声音对上才认为是真的,这个在后面的损失函数的设计上也有所体现。
我们理想的判别器在正确姿势和人下(这里的j是指图像的人和姿势)考虑乐器类别和图像配对时下会认为:
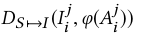 为真
为真
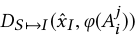 为假(图像是生成的)
为假(图像是生成的)
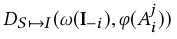 为假(图像和乐器不配对,无论你人是什么姿势只要你用的乐器类别错了就是错的)
为假(图像和乐器不配对,无论你人是什么姿势只要你用的乐器类别错了就是错的)
我们理想的判别器在乐器类别对的情况下考虑演奏乐器人和姿势和图像配对时下会认为:
为真
为假(图像是生成的)
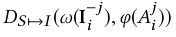 为假(图像中人和姿势与乐器不配对)
为假(图像中人和姿势与乐器不配对)
在判别器这么严苛的判断下,生成器只有生成出乐器图和声音完全配对并且保证人的姿势正确才能以假乱真,否则直接认为是错的,这个对生成的要求是相当高的。
(b)网络大体上和(a)网络类似,但是要相对简单一些,因为只要乐器图像经过编码生成的声音的类别是对的就可以以假乱真了没有太多的姿势和人物限制了。 此时的判别器我想大家应该也理解怎么设置了吧,我这里就不重复叙述了。
模型损失函数分析
我们以S2I的乐器配对前提分析,即
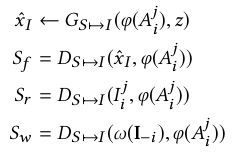
其余的情况还有人物姿势和乐器配对,I2S的情况,我们仅分析这一种情况,剩余的是一样的道理。
此时,对于生成器的损失函数,我们目的是为了最大化这个值:
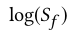
因为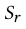 和
和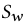 均与生成器无关不需要考虑,
生成器的目的是让判别器D把生成的数据当成真的,就是希望
均与生成器无关不需要考虑,
生成器的目的是让判别器D把生成的数据当成真的,就是希望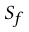 值为1,此时最大化损失函数的目的正是如此。
值为1,此时最大化损失函数的目的正是如此。
对于判别器的损失函数,我们目的是为了最大化这个值:
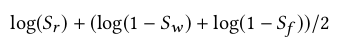
我们优化判别器就是希望能一眼认出真假,就是希望为0,为0,
为1,也就是最大化这个损失函数。
OK!到此,模型的框架和损失函数都已经解释清楚了,我们在一起来了解一下用来做训练的数据集。
剩下只要优化网络就可以出实验结果了,我们一起来看看论文的实验怎么样?
实验数据集
本论文试验阶段选取了两个数据集,我们上面也提到过,一个是Sub-URMP数据集,一个是INIS数据集。Sub-URMP数据集由原始URMP数据集组成,包含13个乐器类别。 在每个类别中,都会录制1到5人播放不同音乐片段的视频。论文将视频分段为0.5秒的小块,使用每个块中的第一帧来表示音频的匹配图像。INIS数据集是从ImageNet收集的, 包含五个类别,每个包含大约1200个图像,采集照片时为了消除噪音,所有图像都要手动选择出来的。我们一起来看看,数据集具体包含什么那些吧:


对于训练集和测试集,文章中大概是8:2分配的:


了解完数据集我们就来正式看看实验效果吧。
CMAV实验
实验中为了说明模型的可行性,将模型做了自我的对比,将模型原始的定义为S2I-C(我们主要分析声音到图像这一路),S2I-N是模型基础上将配对的那一项,
即不考虑,S2I-N是模型不利用GAN的对抗,而是直接利用Autoencoder,即使用MSE来最小化生成图像误差。
我们先来看看这三种状态下的生成效果:

还是有所区别的,整体上S2I-C的效果要优秀一点。
这篇文章的一个值得说的是实验是真的花了功夫的,他们找来了很多人去对在模型不同状态下生成的图像进行打分,打分的标准是:

这些人给出的打分汇总为:
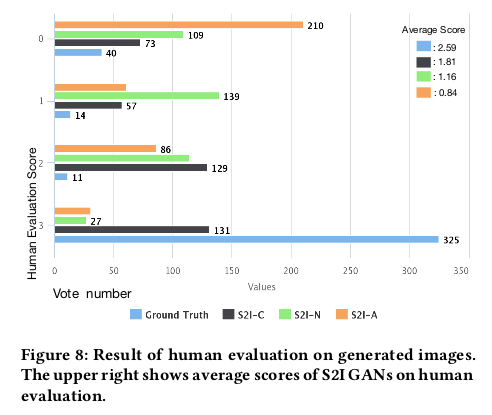
从图中我们可以看出来,除了真实图像外,S2I-C的得分相对另外两种要高出一些,这也证明了模型的可行性。
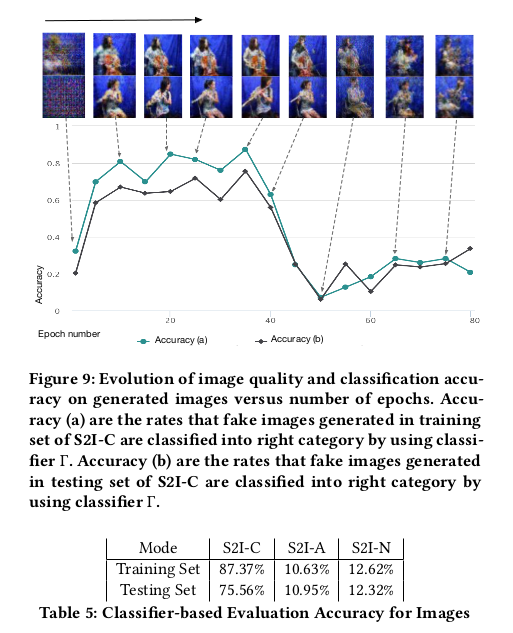
实验还对这几种状态的分类准确性做了比对:
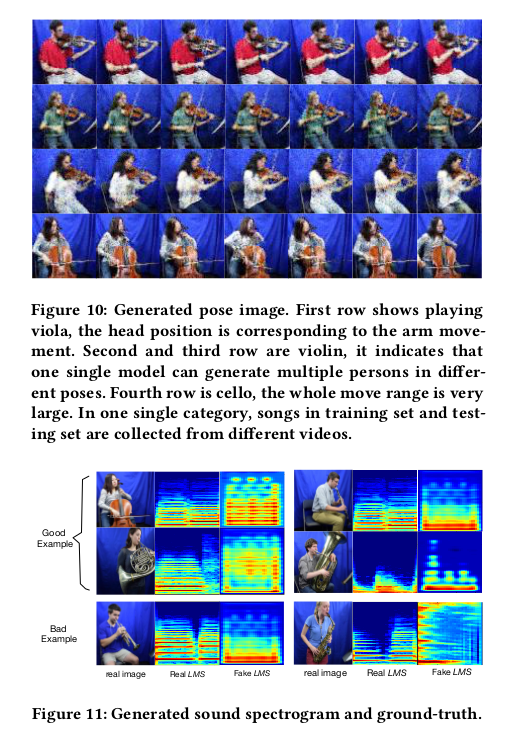
最后就是对于声乐配对上的试验了,展示了人演奏音乐的姿势的声音关系:
总结
论文实现了声音和乐器图相互转换生成,实现了跨模态互相生成的先河。文章的主题是利用GAN实现的,通过实验展示了模型的合理性,在实验的过程中, 作者实事求是把模型遇到的问题和不足都做了说明,具有不错的指导意义。但是GAN自身的图像生成过程中的扭曲任然在文中有所体现, 最终的声音生成还有待通过专业分析来加以验证。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







