CMCGAN论文解读
近期接触了跨模态生成领域,由于我前期研究方向一直是GAN所以我是尽量找一些将跨模态和GAN结合的文章研读。17年底由中科院发表的CMCGAN实现了声音和视觉图像的相互转换, 就是结合了GAN和Cross-Modal,今天我们一起来解读一下这篇论文吧。
引入
跨模态的转换和配对对于处理多媒体文件是十分重要的。举个例子就我们日常的监控视频或者就是普通的音乐视频而言,这些视频都是由很多帧的图片和对应的声音构成。 一旦视频出了问题,比如监控视频的声音传感器坏了导致的视频声音丢失或者是视频拍摄的设备出问题导致视频很模糊甚至没有图像仅有声音情况下, 这时由剩下的一种模态还原另一种模态就是相当重要的了。如果我们学习到了由视频声音可以还原图像,或者由视频图像还原声音的话,这个问题就可以解决了。 CMGAN就是在这样的假设下提出来的,文章的实验中实现了音乐声音和对应的演奏乐器图片相互转换生成。虽然文章没能实现在视频中将声音和图像相互转换, 但是这个思想对于这方面的发展还是有一定指导意义的。
CMGAN实现了以下几点的创新:
1.提出了跨模态循环对抗网络(CMGAN)处理了视觉图像到声音的相互转换生成。
2.文章在处理图像和声音在编码后维度和框架不同时,提出了在feature后加上latent vector解决了此类问题。
3.提出了联合对抗损失函数,不仅仅是区分生成数据和真实数据还可以用来检查图像和声音是否配对。
4.提出了多模态分类器网络用于动态分类出声音和图像。
CMGAN模型介绍
文章花了很大的力气在阐述visual<–>audio相互生成的过程,但是这部分的核心思想来源于CycleGAN的思想,我们通过模型的网络结构图来说明。
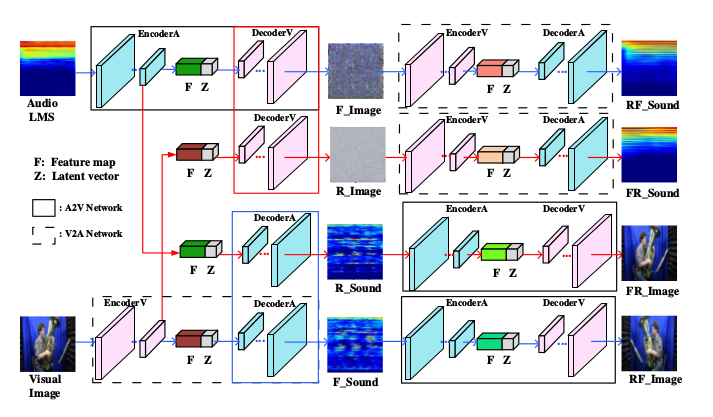
文章中对于声音数据的处理是先将声音文件转换成对应的频谱图,然后通过图像之间的转换实现声音和图像之间转换的,这类方法已经在很多论文中都有所应用了。
我们看看这张网络模型图,可以看到有很多的编码器和解码器,同颜色的矩形框下的解码器(Decoder)是共享参数的,就是上图左侧的红色框和蓝色框下的Decoder其实是同一个网络, 这个在模型上十分重要我们待会详细说明。F_image为声音经过编码后解码得到的,F_sound为图像经过编码后解码得到的,R_image图像经过编码后解码得到的, R_sound声音经过编码后解码得到的。F为数据经过编码得到的特征层,z为潜藏向量。矩形实线框为audio–>visual,矩形虚线框为visual–>audio。 RF_sound为声音频谱图到声音频谱图,其余的几个意思和这个类似,我就不一一解释了。
把这个网络看一遍后如果你是第一次看或者仅仅是通过我的这篇博客来看是不是觉得一头雾水,现在我们一起来梳理一遍。
我们知道通过Autoencoder可以实现数据的重构,对于图像我们对其编码(encoder)后得到 feature map 然后经过解码(decoder)可以重构出这张图像。 但是想由频谱图编码再解码成乐器图是不可能实现的,文章受到CycleGAN的启发实现了这个转换。首先输入一张声音频谱图经过编码得到特征层F加上潜藏向量z后解码可以得到重构的声音频谱图R_sound, 对应上图就是左边第三个解码器Decoder,这个是我们Autoencoder的思想。相对应的我们输入一张乐器图像经过编码得到特征层F加上潜藏向量z后解码可以得到重构的乐器图R_image, 对应上图就是左边第二个解码器Decoder。如果我将声音频谱图编码后F和z结合后通过第二个解码器Decoder会生成什么呢?会不会得到乐器图? 答案是可以的,只要我将第二个解码器Decoder通过网络优化就可以实现声音频谱图编码后解码生成乐器图,当然这个图像不一定乐观,所以这时我们再经过一轮编码解码就可以实现较好的转换了。 所以这就是为什么第一个解码器和第二个解码器共享同一参数,第三个个解码器和第四个个解码器共享同一参数的原因了。 就是如果我单纯对图像重构是不可能得到另一种图像的,我们通过在编码得到的feature map和潜在向量z结合通过Decoder这个跳板就可以实现图像之间的转换了。 我们这样分析一遍是不是感觉这个模型也就这么回事,这就是这个模型的创新所在了。
联合对抗损失函数
文章提到自己的一大贡献就是提出了联合对抗损失函数,其实就是GAN的损失函数的变形而已。我们来看看判别器的损失函数:
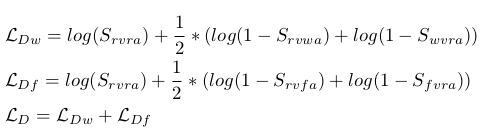
这里面的参数也是有点绕,首先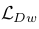 用于判别(图像,声音)是否来自相同的乐器类别,
用于判别(图像,声音)是否来自相同的乐器类别,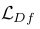 用于判别(图像,声音)是生成的还是真实的。它们之和用作判别器的损失函数,
用于判别(图像,声音)是生成的还是真实的。它们之和用作判别器的损失函数,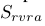 是真实图像和声音对,
是真实图像和声音对,
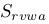 是在错误类别下真图真声对,
是在错误类别下真图真声对,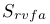 是真类别下的真图假声。
其余的定义都是差不多的意思了。感觉有点绕,说白了就是我已经准备好了一些配对的图像和声音。这些配对好的有是正确关联的类别,还有就是错误关联的类别对,
通过训练的时我尽量想得到真确类别对应的配对图像和声音。
是真类别下的真图假声。
其余的定义都是差不多的意思了。感觉有点绕,说白了就是我已经准备好了一些配对的图像和声音。这些配对好的有是正确关联的类别,还有就是错误关联的类别对,
通过训练的时我尽量想得到真确类别对应的配对图像和声音。
对于生成器的损失函数:
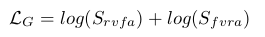
这个没多少必要说的了,和GAN的思路都是差不多的,对应上面的判别器损失函数。
最后在训练的时候,还提到了联合的损失Consistency Loss:
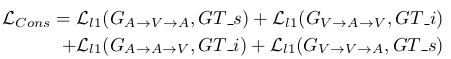
这里是将中间的编码解码的损失函数放在一起优化的联合损失,对于模型的实现非常有意义。
下面是文章实现的算法伪代码:

我感觉这个算法给的不够详细,中间的一些细节没说明白,这篇文章的代码也是没公布,也是满希望作者能公布代码的。
CMGAN实验
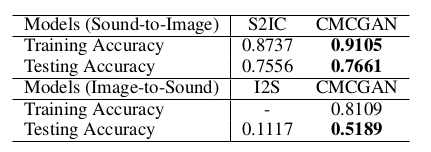
实验这一块,CMGAN首先将自己的模型和已有的声音和图像之间转换的S2IC模型在数据配对准确率上做了对比:
然后又在视觉上做了对比:
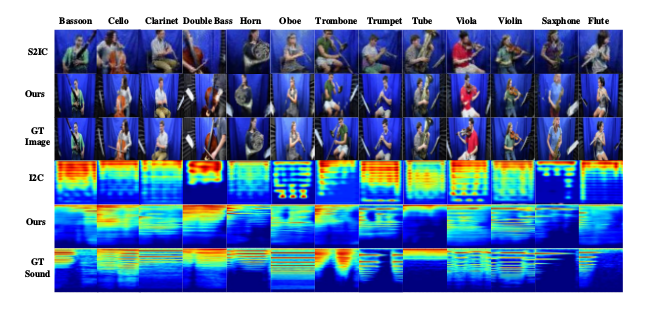
确实实验结果上得到了一定的提升。
接下来,通过对比CMGAN跨模态转换的有无说明图像和声音的关联和配对信息的重要性:
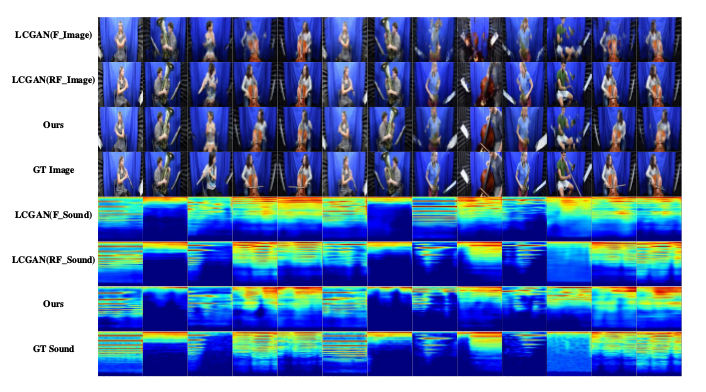
去掉Latent vector z会怎么样?实验也做了对比:
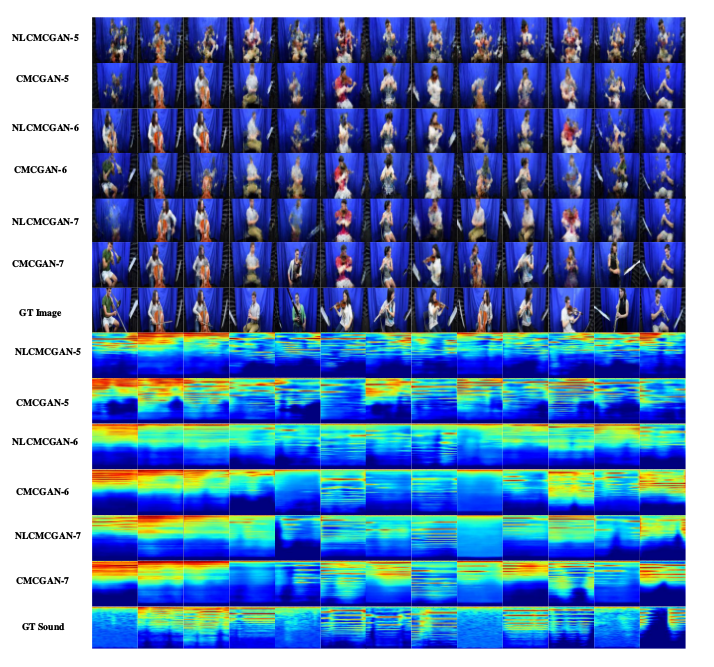
又说明了自己的联合对抗损失函数的重要性,通过不同的损失函数的带入得到的结果:

最后实验说明了文章提到的动态多模态分类器的作用,分类器结构如下:
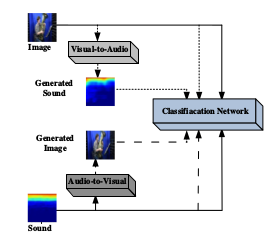
通过对模态的分类可以提高配对的准确率:

总结
文章通过CycleGAN的思想实现了visual<–>audio的相互转换,对于处理视频中确实一类模态的还原具有一定的指导意义。
但是我们知道GAN生成的图像如果不做处理的话容易发生扭曲和不合理,这在实验部分的图中可以很清晰的看出来,拿这样的结果去做还原还是远远不够的。 还有就是生成的频谱图,在试验中并没有还原为声音这对于检验生成的真实合理性上有所欠缺。文中大部分的实验对比只是单纯的肉眼区分实验好坏, 大篇幅的实验在说明自己模型的结果合理性没有实质性的对成果进行说明。文章对于网络的细节描述上个人感觉不太清晰,对于中间的联合损失函数没有展开说明, 我对这个看的有点不太清晰。
当然上述只是我的个人看法,毕竟这篇文章是中了CVPR的,文章质量肯定是毋庸置疑的。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







