IMDB-WIKI-500k+人脸数据集年龄整理的那些事
IMDB-WIKI-500k+人脸数据集是为数不多的包含人脸年龄的数据集,拿到这个数据集如何去处理里面图片信息年龄是一个蛮大的问题, 这个问题在中文资料里写的特别的少,我之前写论文时做过人脸年龄预测生成的实验所以我整理了这个数据集,这里面是个巨大的坑,而且一不注意就会让你的生成惨不忍睹。 今天我们一起来看看如何处理IMDB-WIKI-500k+人脸数据集。
数据集简介
IMDB-WIKI 500k+ 是一个包含名人人脸图像、年龄、性别的数据集,图像和年龄、性别信息从 IMDB 和 WiKi 网站抓取,总计 524230 张名人人脸图像及对应的年龄和性别。 其中,获取自 IMDB 的 460723 张,获取自 WiKi 的 62328 张。具体数据集的下载可在我的另一篇博客中找到.
下图是官方给的IMDB-WIKI 500k+ 里的示例图片,大家看看就好:

当然你在整理这个数据集的话你会发现这个数据集里的大部分照片都是质量不高的,其实是这样的:
至于年龄信息标注吗?我只能说官方给的年龄段统计是这样的:
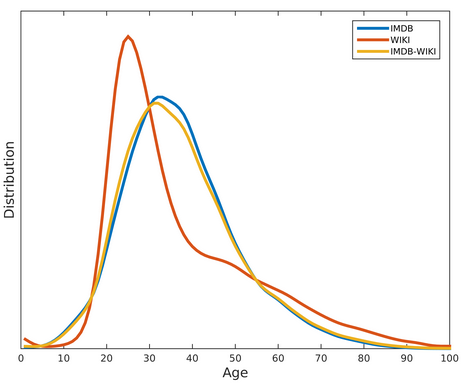
你要是自己把年龄信息相对应的图片都提出来你会发现有部分图片出现了年龄与图片不符的情况,这个也是后来用来做生成出现问题的一大难点,我们之后再说。
对于图片的信息标注,数据集下有两种格式,我们先来看看:

上面两种是一种格式的标注,下面两种属于一种标注。两种形式不变的是都会有图片人物的出生日期和拍摄日期。有这两个条件就可以提取出照片中人物的年龄了。 当然了,这个数据集下有一个打了标注的.m文件,我感觉处理起来不是很舒服我就干脆直接没用。
我们接下来就来细细说说怎么处理这个数据集让它能够把年龄分出来,并且可以用来做生成。
提取年龄图片
我们举例看一下图片标注的第一种格式为9141321981-12-09_2010.jpg,怎么把这类标注对应的图片提取出来呢,其实并不难处理。我们仔细观察一下这类标注, 在标注遇到第一个” _ “时后面接着的是人物出生日期,遇到第二个” _ “时后面接的是人物图片拍摄年份。拍摄年份-出生年份=人物图片年龄,这个也就是我们需要的年龄图片信息。 一般情况下”“后的四个字符就是我们需要的年份信息,我们可以利用这个信息来提取出年份信息,我们看看用代码是怎么实现的:
import os
list = os.listdir(Agepath)
for i in range(0, len(list)):
imgName = os.path.basename(list[i])
if os.path.splitext(imgName)[1] != ".jpg":
continue
if i % 50==0:
print(imgName)
for j in range(0, len(imgName)):
if imgName[j] == "_":
age1 = imgName[j+1:j+5]
for n in range(j+1, len(imgName)):
if imgName[n] == "_":
age2 = imgName[n+1:n+5]
age = int(age2) - int(age1)
这里的Agepath就是我们的数据集图片对应的地址,首先我们通过遍历找到第一个” _ “的位置,然后将后四位字符存储到age1数组里(此时数组的形式默认为字符串类型), 然后我们在之后通过便利剩余字符找到第二个” _ “的位置,然后将后四位字符存储到age2数组里。此时两个数组的格式都是字符串类型,但是里面存储的是数字, 所以我们简单的通过将数组转换为int型就可以转换为数字数组了。我们知道拍摄年份一定大于出生年份,所以我们就放心大胆的减就可以得到这张照片对应人物的年龄了。
得到这张照片的年龄后我们只需要将这张照片通过shutil模块移动到我们需要的位置就好了,当然了这个你可以根据你自己的需要移动,比如说我就想找35岁的人物, 你只需要加个判断语句就OK了。
import shutil
oldname = Agepath + imgName
if age == 35:
newname = Agepath1 + imgName
shutil.copy(oldname, newname)
这里的Agepath1为你要移动到的路径。
对于第二种格式的图片,举例来说即这样的nm000381_rm887915520_1962-7-19_1994.jpg,我们完全可以参考上面的方法不过这里需要变动一点点了, 因为这里年份信息是在第二个” _ “的位置和第三个” _ “的位置后。整体思路不变我们可以这样操作:
import os
list = os.listdir(Agepath)
for i in range(0, len(list)):
imgName = os.path.basename(list[i])
if os.path.splitext(imgName)[1] != ".jpg":
continue
if i % 50==0:
print(imgName)
for j in range(0, len(imgName)):
if imgName[j] == "_":
for k in range(j+1, len(imgName)):
if imgName[k] == "_":
age1 = imgName[k+1:k+5]
for n in range(k+1, len(imgName)):
if imgName[n] == "_":
age2 = imgName[n+1:n+5]
age = int(age2) - int(age1)
其他地方的处理和第一种格式完全相同。
OK!上述处理后你就可以得到你想要的年龄段分好的图片了,由于只是处理字符串,整个过程非常的快,普通的电脑估计1分钟可以处理不下于一万张左右的图片。
处理提取后的图片
当你满心欢喜的打开你已经按照年龄段整理好的图片文件夹后,开心的心情就会被泼一盆水,因为你会发现在你的文件夹下存在着年龄信息和实际图片不符合的图片、灰色图片和一些场景变形的图片, 最为气愤的是由于你需要用来做生成对于图片的要求很高的,但是这里有太多的侧脸!侧脸!侧脸照,你爬数据能不能爬那些看镜头的照片啊! 还有一个大问题就是图片的尺寸不同意,大小参差不齐,有的是236x236,有的甚至是73x73,还有的达到的500x500。
这样一系列的问题让你的心情一落千丈,坦白说人脸数据集我也接触过一些,我认为做的最为仔细的就是celebA数据集了,照片良心大小合适,这个数据集让人头大。
首先说一下,怎么处理这样一堆扎眼的图片。我是将数据分为很多的子文件夹通过判断RGB通道删除了灰色图片,对于场景变形的图片、年龄不符合的图片和侧脸非常明显的我们只能通过人工来删除了。 其实如果你整理的多的话对于挑选照片还是一件比较轻松的活,听听歌的功夫就可以整理出很多的照片,如果赶时间建议多些人一起吧, 数据集做的越细致你的生成效果就会越好,这个是毋庸置疑的。在整理数据集的这段时间我也是尽量享受这个过程吧,也算是一种另类的放松, 因为我电脑还跑者别的实验所以基本上也不算耽误我的时间吧。
OK!整理完我的图片以后,我们就需要对这些数据送入模型训练了,我按照文件夹将数据分好打上年龄段标签然后就是整理包装训练了。
整理数据送入训练
对于图片尺寸问题,我是强制性让图片尺寸resize到200x200. 这个就带来了一个必要的问题就是对于尺寸远小于200x200的图片造成了一定的失真,这个问题是无法避免的。
另一个问题就是IMDB-WIKI人脸数据集的人脸的大小和位置在每张图片上是有差异的,有的照片脸特别大,有的照片脸特别小,还有就是存在大量的侧脸图片, 如果统一再分出人脸位置的话是相当麻烦的。IMDB-WIKI人脸数据集是可以用来做人脸位置检测的数据集,但是这样乱七八糟的人脸位置导致了做图片生成时候的麻烦。 根本上解决这个问题只能从数据集本身出发了,实验上只能尽量的减小这个问题。我在训练过程中对已经resize的人脸通过取一定比例的crop来尽量取到相适应的人脸, 对于大部分图片是可行的但是也有部分图片经过crop后人脸大小上不合适,这就带来了训练结果不理想的情况。
之前我们训练人脸的数据集celebA中图片的大小尺寸是统一的、图片的人脸位置是统一的,人脸的大小是基本相当的这就是celebA用来做图片生成上效果好的主要原因。 IMDB-WIKI人脸数据集对于人脸检测来说应该没问题但是拿来做图像生成是不够理想的。我尝试找了一下包含年龄信息的数据集,目前免费的就这一个, 所以只能根据实验做相应的调整来优化实验结果。我总结了一下改进训练结果的几点:
1.目前我整理了不到10万张的图片,在深层网络下还有点少了,我手头还有大概10万多的图片没有整理,但是就单纯做人脸生成10万张图片已经足够了,这个不是根本的问题。
2.人工将图片统一,删除数据集里的侧脸和位置不对的图片,将尺寸特别小的图片也删除。这个就带来了大量的人力物力,我感觉也没这个必要,当然你要是想在这方面发文章你最好把数据集好好再整理一下。
3.将部分celebA数据集图片加入到IMDB-WIKI人脸数据集里共同来做训练,这样就好比是用优等生来带差等生,最后的平均成绩会有所提高, 但是celebA不包含年龄信息只有一些Old照片可以直接用,我手动将部分图片按照年龄预估加入到了IMDB-WIKI人脸数据集里,但是实验结果会有一定影响。
4.优化网络参数,这个基本上不会有实质性的提高,因为模型参数已经在celebA上取得了不错的实验结果。
综上我选择了将部分celebA数据集图片加入到IMDB-WIKI人脸数据集里共同来做训练,实验结果是比不上直接用celebA数据集的效果的并且出现了一定年龄段的空层。 但是整体实验效果是出来了,勉强能看吧:

温馨提示
如果你是用这个数据集来做预测的话,恭喜你!这个数据集应该问题不大。但是如果你是用来做生成的话你还需要好好优化优化你的数据集。
最后我将整理的两种类型你年龄的代码传至github上了,可以查看:
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







