Light-Head R-CNN简析(转)
Light-Head R-CNN是旷视和清华大学在COCO 2017比赛拿到冠军的算法。这些大牛的参赛经验就是厉害啊! 我感觉我们这样的小实验室在目标检测这类比赛根本就做不起来,不过还是看看这个优越的算法吧!本文的原博客在这里。
算法原理
目前object detection算法主要分为one stage的SSD、YOLO;two stage的Faster RCNN、R-FCN、Mask RCNN等。前者速度快,但是精度低;后者速度慢, 但是精度高,因此现在object detection的研究方向主要在于如何取得速度和精度两方面的共同进步。这篇文章的出发点是: 为什么tow stage的object detection算法速度会比one stage的object detection算法慢那么多?于是作者通过对Faster RCNN和R-FCN这两种two stage的object detection网络分析找到原因, 并针对原因来改进模型达到速度和精度的提升,实验结果部分可以仔细看看。
这篇文章的网络名为Light-Head RCNN,这是因为作者将two stage的object detection算法的网络结构分成两部分,一部分是region proposal(或者叫ROI)的生成过程(文章中命名为body部分), 另一部分是基于ROI预测框的过程(文章中命名为head部分)。对于像Faster RCNN、R-FCN这样的two stage的object detection算法,第二部分有一些操作耗时且存储量较大, 因此称为heavy head。而本文的light head RCNN则是通过对第二部分的修改减少了许多复杂操作,所以称之为light head。
先来感受下Light-Head RCNN算法和其他算法相比的提升情况。Figure1是Light-Head RCNN算法和其他object detection算法在速度和准确率上的直观对比,可以看出在这两方面的优势还是很明显的。
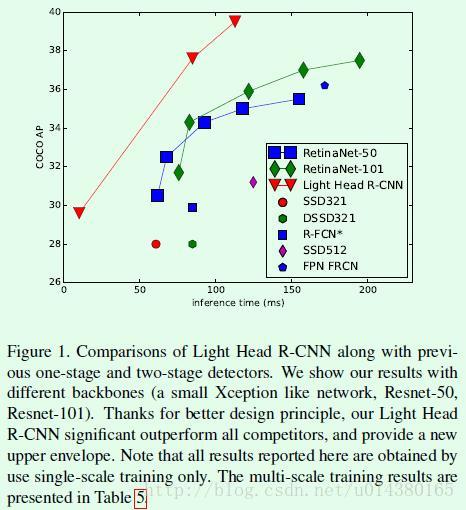
Light-Head RCNN的主网络主要采用ResNet101(文中用”L“表示)或Xception(文中用“S”表示),前者的精度较高(比目前two stage的算法要高), 后者的速度较快(比目前one stage的算法要快),可以看最后的实验分析。
Figure2介绍的是Faster RCNN、R-FCN和本文的Light-Head RCNN在结构上的对比。在Figure2中的三个网络,大体上都可以分成两大部分:RCNN subnet和ROI warping, 其实严格讲还有一部分是分类网络提取特征,而这三个部分之间的关系大概是这样的:ROI warping以分类网络提取到的特征为基础来生成ROI, 而RCNN subnet则是以分类网络提取到的特征和ROI warping生成的ROI为输入来做分类和回归的。因此Figure2中三个网络结构中的虚线框部分的输入除了箭头所示的用分类网络提取的feature map外, 还包括RPN网络生成的ROI。
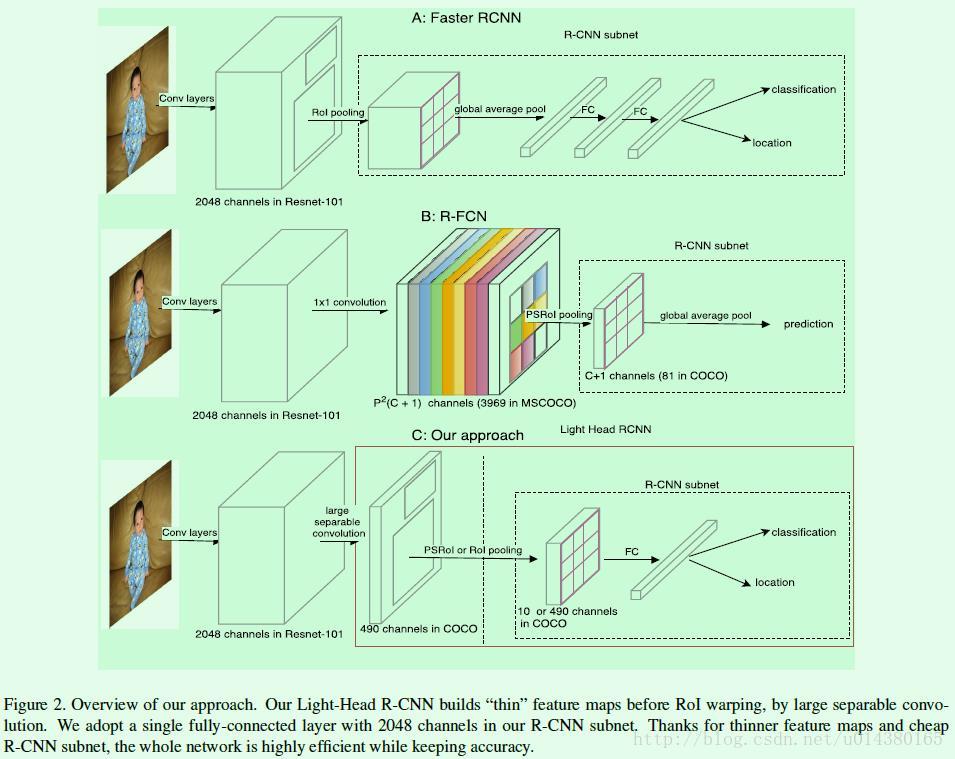
Faster RCNN中,先用分类网络(原论文中是用VGG)提取特征得到2048维的feature map。然后是一个ROI Pooling层,该层的输入包括前面提取到的2048维的feature map, 还包括RPN网络输出的ROI,根据这两个输入得到ROI尺寸统一的feature map输出,比如都是3 * 3大小或7 * 7大小的feature map。然后经过两个全连接层(参数数量较多), 最后有两个分支分别做分类和回归。Faster RCNN因为要将每个ROI都单独传递给后面的RCNN subnet做计算,因此存在较多重复计算,所以比较耗时; 另外两个channel都是几千的全连接层的存储空间占用也是比较大的。
R-FCN主要解决了Faster RCNN中ROI Pooling层后重复计算的问题。在R-FCN中,先用分类网络(ResNet)提取特征得到2048维的feature map(原文中该层后面会跟一个channel数量为1024的1 * 1卷积用于降维)。 然后用channel数为P^2(C+1)的1 * 1卷积来生成position-sensitive的score map,也就是Figure2 B中彩色的那些feature map, 这是分类的支路(回归的支路是用channel数为P^2(8)的1 * 1卷积来生成,在Figure2中未画出)。然后经过一个PSROI Pooling层生成C+1维的feature map,feature map的大小是P * P, 该层的输入包含前面一层生成的score map,还包括RPN网络生成的ROI。最后经过一个global average pool层得到C+1维的1 * 1feature map, 也就是一个vote过程,这C+1维就是对应该ROI的类别概率信息。关于R-FCN算法的详细介绍可以参考:R-FCN算法简析。 R-FCN因为要生成额外的一个channel数量较多(channel数量为classes * p * p,如果在COCO数据集上是81 * 7 * 7=3969)的score map作为PSRoI Pooling的输入,所以在存储和时间上都有不少消耗。
Light-Head RCNN 如Figure2 C所示,基本上是在R-FCN基础上做的修改。针对R-FCN中score map的channel数量较大, 作者采用一个large separable convolution生成thinner feature map(large separable convolution可以参看下面的Figure3), 其实就是将原来$P^2(C+1)$的channel数量用$P^2*10$来代替,差不多是从3969降低到490,这样就降低了后续Pooling和其他操作的计算开销。 Figure2 C中,这490维的feature map如果作为PSROI Pooling的输入之一(另一个输入是ROI),就可以得到channel数为10的输出; 如果这490维的feature map是作为ROI Pooling的输入之一(另一个输入是ROI),那么就可以得到channel数为490的输出。 最后加上全连接层是因为前面large separable convolution操作对channel做了改动,所以后面没法直接做分类, 需要用一个全连接层做通道数量的转换,才能接classification和location两个分支。
从Figure2中的前两个网络可以看出,二者在ROI Pooling后都采用了global average pooling,这种操作显然对object的定位不是很有利, 因为pooling操作会丢失位置信息,所以在light head RCNN中就去掉了这样的层。
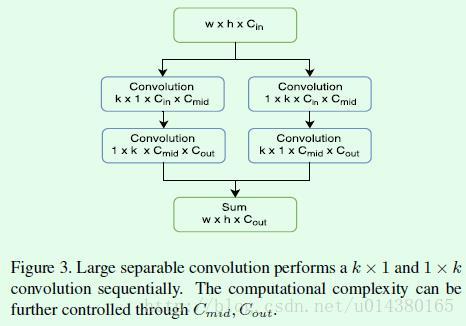
Figure3是large separable convolution的示意图,文中是通过这个生成Figure2中channel数为490的feature map,也就是文中说的thin feature map。 从Figure3可以看出,这种结构是借鉴了Inception 3 中将卷积核大小为k * k的卷积操作用1 * k和k * 1的两层卷积来代替的思想,计算结果是一致的, 但是却可以减少计算量(差不多可以减少为原来的k/2,在文中作者k取15,也就是用了一个尺寸较大的卷积核)。对于S主网络,Cmid采用64;对于L主网络, Cmid采用256。Cout就是前面说的channel数量490(10 * p * p,p为7)。
实验结果
文中的实验主要是在COCO数据集上做的,该数据集包含80个类别的object,训练集有80K,验证集有35K,测试集有5K。作者用训练加验证共115K的数据训练,然后用5K的测试集做验证。
首先table1中的B1是标准的R-FCN算法的结果。B2则是在B1的基础上做了如下改动:
1、将输入图像的短边resize到800,限制最长边为1200。
2、将回归损失的权重加倍。
3、根据损失排序选取损失最大的256个samples回传损失。
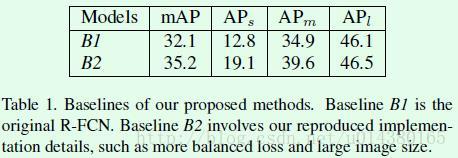
Figure4主要来验证前面提到的thin feature map对于检测效果是否有提升(其实和前面Figure2 C是一样的)。具体来说是这样的,原来在R-FCN中, PSROI Pooling层的输入feature map的channel数量是P^2(C+1),对于COCO数据集,C=80,对于Pascal VOC数据集,C=20,P的话在R-FCN原文中是设置为7, 因此对于COCO数据集,channel数量应该是7^2 * 81=3969。而在Figure4中,在PSROI Pooling层之前会先用一个channel数为10(C+1)的1 * 1卷积对输入做channel的缩减 (因此对于COCO数据集,channel数量应该是7^2*10=490),也就是构造thin feature map,然后再将缩减后的feature map作为PSROI Pooling层的输入。 因此这样的修改使得原来在R-FCN网络中分类支路最后的vote操作没法在修改后的网络进行,因此在Figure4中用一个全连接层来连接PSROI Pooing层的输出, 然后再连classification和location两个分支。
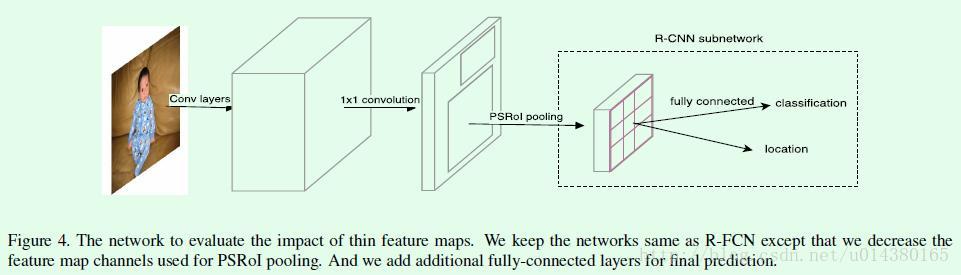
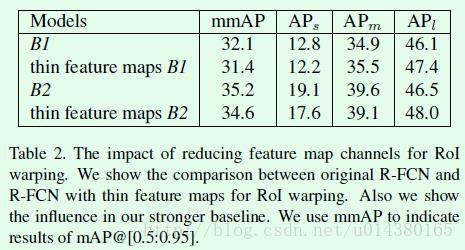
Figure4的网络效果怎么样呢?可以看下面的Table2。可以看出对精度的影响不算大,但是速度的提升可想而知。另外作者强调了引入这种通道缩减的操作后, 将该网络和FPN(feature pyramid network)结合才有可能实现,因为如果按照原来R-FCN的网络情况,要和FPN结合(也就是对不同尺度的层做position-sensitive pooling)其计算量是非常大的。
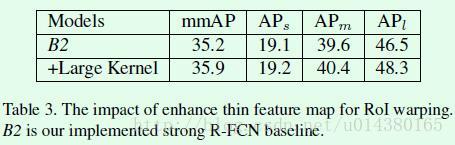
如果用文中介绍的large separable convolution来替代原来的1 * 1卷积效果怎么样?可以看table3,效果有一点提升,当然我相信主要的提升是在速度上。
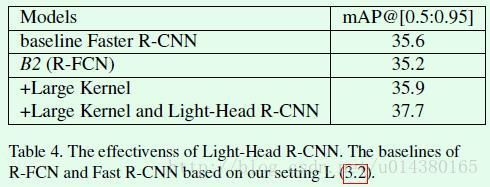
前面的table2和table3分别介绍了thin feature map和large separable convolution的效果,下面table4的最后一行就是将这二者结合后的效果,mAP达到了37.7。
前面介绍的算是本文的主要创新点,下面table6中列举的3个trick可以继续提升模型的效果。比如Mask RCNN中提到的RoIAlign,用来改进PSROI Pooling,可以有1.3的提升。
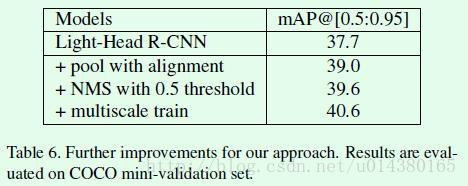
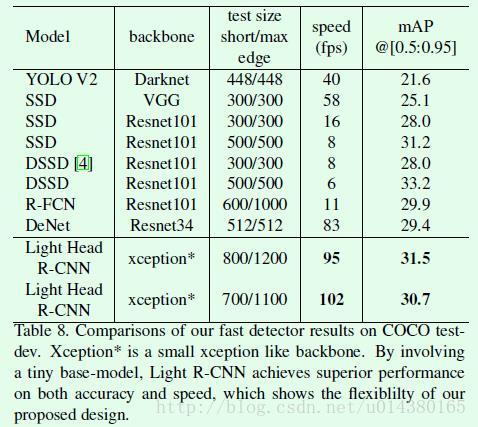
最终的对比结果是后面这两个表。
table5是主网络采用ResNet101的Light head RCNN和其他object detection算法在mAP方面的对比。
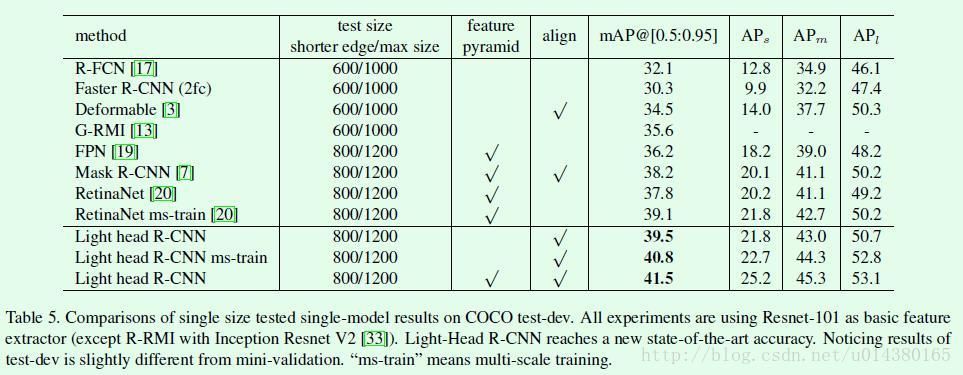
table8是主网络采用xception的Light Head RCNN和其他object detection算法在速度的对比。可以看出相比YOLO V2、SSD系列、R-FCN等算法不管在速度还是精度上都有提升。
总体上看,主要是对PSROI Pooling层的输出feature map做通道上的缩减,提高了速度;同时去掉了原来R-FCN或Faster RCNN中最后的global average pooling层, 一定程度上提升了准确率。再加上其他一些操作比如pooling with alignment、NMS、multiscale train、OHEM等进一步提升效果。 两种不同的主网络,要精度有精度,要速度有速度,可以根据需要灵活选择。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







