DSSD(转)
DSSD在SSD基础上加入了额外的上下文信息,将目标检测精度提高了不少,今天我们就老看看DSSD,本博客原文在这里。 抽空我会把DSSD论文详细看看,再做分析。
Abstract
- 本文的主要贡献在于在当前最好的通用目标检测器中加入了额外的上下文信息。
- 为实现这一目的:我们通过将ResNet-101与SSD结合。然后,我们用deconvolution layers来丰富了SSD + Residual-101, 以便在物体检测中引入额外的large-scale的上下文,并提高准确性,特别是对于小物体,从而称之为DSSD。
- 我们通过仔细的加入额外的learned transformations阶段,具体来说是一个用于在deconvolution中前向传递连接的模块,以及一个新的输出模型, 使得这个新的方法变得可行,并为之后的研究提供一个潜在的道路。
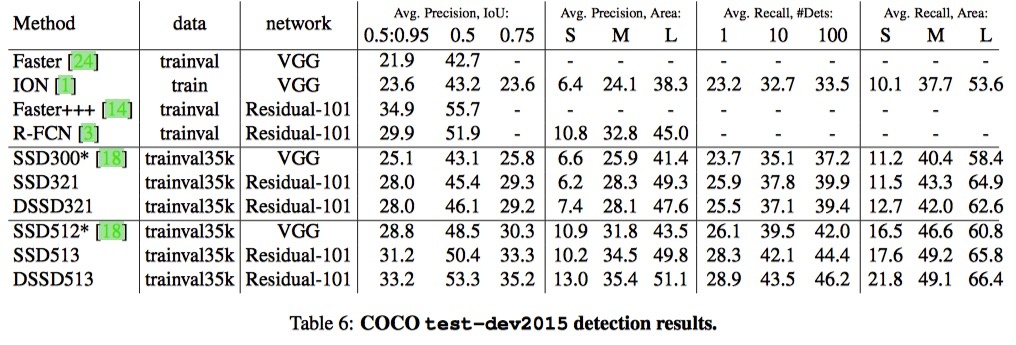
- 我们的DSSD具有513×513的输入,在VOC2007测试中达到81.5%de的mAP,VOC2012测试为80.0%de的mAP,COCO为33.2%的mAP,在每个数据集上优于最先进的R-FCN 。
Introduction
最近的一些目标检测方法回归到了滑动窗口技术,这种技术随着更强大的整合了深度学习的机器学习框架而回归。
Faster RCNN -> YOLO -> SSD.
回顾最近的这些优秀的目标检测框架,要想提高检测准确率,一个很明显的目标就是:利用更好的特征网络并且添加更多的上下文,特别是对于小物体, 另外还要提高边界框预测过程的空间分辨率。
在目标检测之外,最近有一个集成上下文的工作,利用所谓的“encoder-decoder”网络。该网络中间的bottleneck layer用于编码关于输入图像的信息, 然后逐渐地更大的层将其解码到整个图像的map中。所形成的wide,narrow,wide的网络结构通常被称为沙漏。
但是有必要仔细构建用于集成反卷积的组合模块和输出模块,以在训练期间隔绝ResNet-101层,从而允许有效的学习。
Related Work
SPPnet, Fast R-CNN, Faster R-CNN, R-FCN, YOLO:使用卷积网络的最上面的层来进行不同尺度的物体检测。
通过在ConvNet中开发多层来提高检测精度的方法有多重。
第一种方法:组合了ConvNet不同层的特征图,并使用组合特征图进行预测。
ION利用L2 normalization来结合多个VGGNet和池化层的特征来进行目标检测。
HyperNet也是使用类似于ION的方法。
但是这种结合多层特征的方法不仅增加内存,而且降低了模型的速度。
第二种方法:使用ConvNet中的不同层来预测不同尺度的对象。
因为不同层中的节点具有不同的接收域,所以自然会从具有大型接收场的层预测大对象,并使用具有小接收场的层来预测小物体。
SSD将不同尺度的默认框扩展到ConvNet中的多个层,并强制执行每一层专注于预测一定规模的对象。
S-CNN [2]在ConvNet的多层应用去卷积,以在使用层去学习region proposal和pool feature之前增加feature maps的分辨率。
然而,为了很好地检测小物体,这些方法需要从具有小的接收场和密集特征图的浅层中使用一些信息,这可能导致在检测小对象性能较低,因为浅层具有较少的关于对象的语义信息。
通过使用deconvolution layers和skip connections,,我们可以在密集(去卷积)特征图中注入更多的信息,从而有助于预测小物体。
另外还有一个工作方法,尽量去包括预测的上下文信息。
Multi-Region CNN
Deconvolutional (DSSD) model Single Shot Detection
SSD
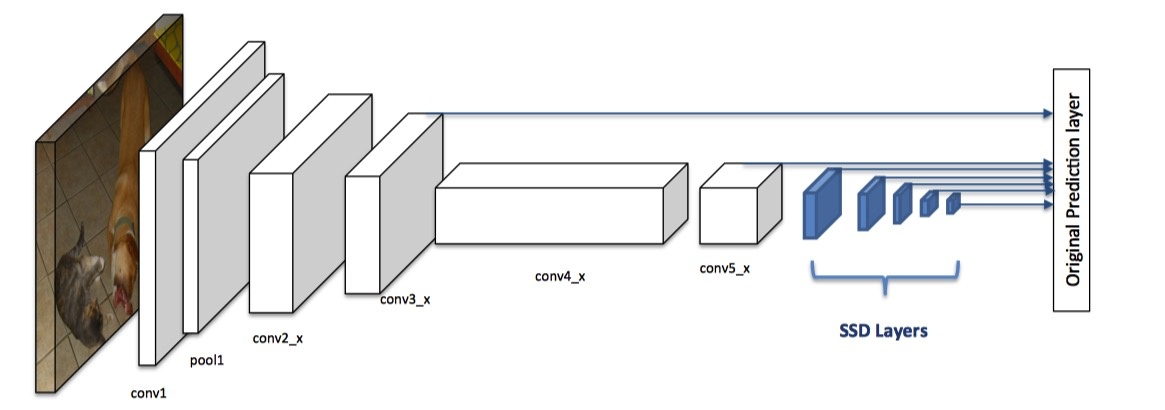
SSD构建于base network之上,添加了一些逐渐见效的卷积层,如上图蓝色部分。
每个添加的层和一些较早的基本网络层用于预测某些预定义的边界框的分数和偏移。
这些预测由3x3x#个通道维数的滤波器执行,一个滤波器用于产生每个类别分数,一个用于回归边界框的每个维度。
它使用非最大抑制(NMS)对预测进行后处理,以获得最终检测结果。
Using Residual-101 in place of VGG
将Base Network从VGG16换为ResNet-101并未提升结果,但是添加额外的prediction module会显著地提成性能。
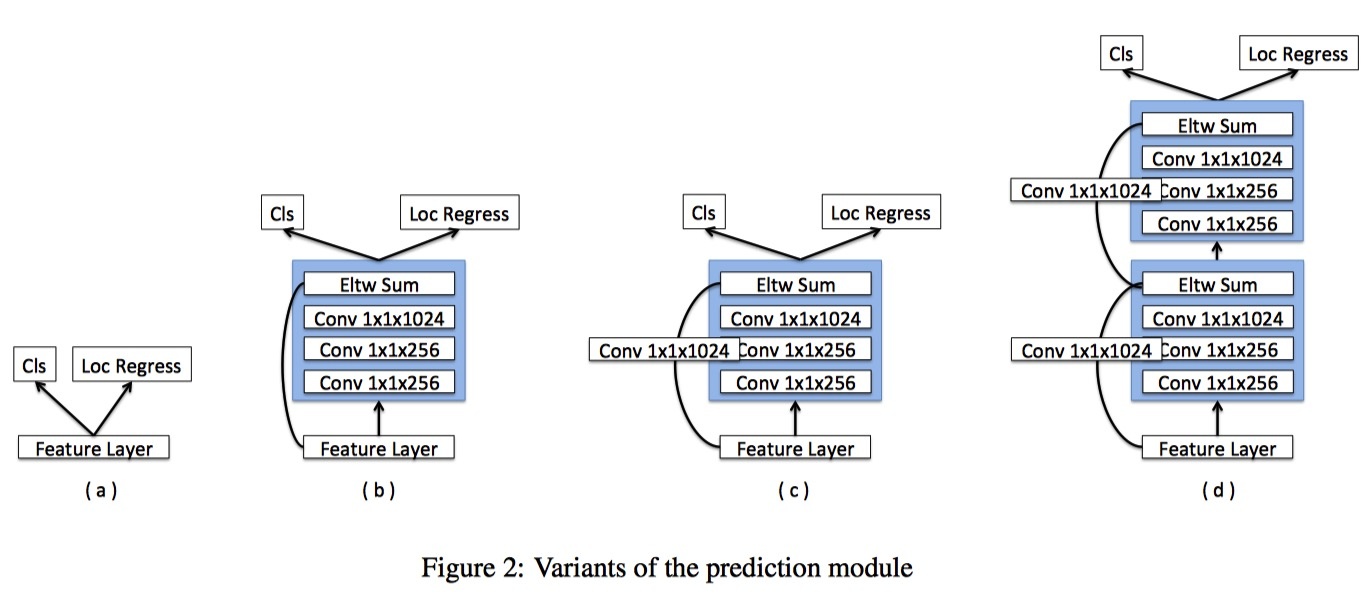
在原始SSD中,目标函数直接应用于所选择的特征图,并且由于梯度的大幅度,使用L2标准化层用于conv4 3层。
MS-CNN指出,改进每个任务的子网可以提高准确性,按照这个原则,我们为每个预测层添加一个残差块,如图2变体(c)所示。
我们还尝试了原始SSD方法(a)和具有跳过连接(b)的残余块的版本以及两个顺序的残余块(d)。 我们注意到,ResNet-101和预测模块似乎显著优于对于较高分辨率输入图像没有预测模块的VGG。
Deconvolutional SSD
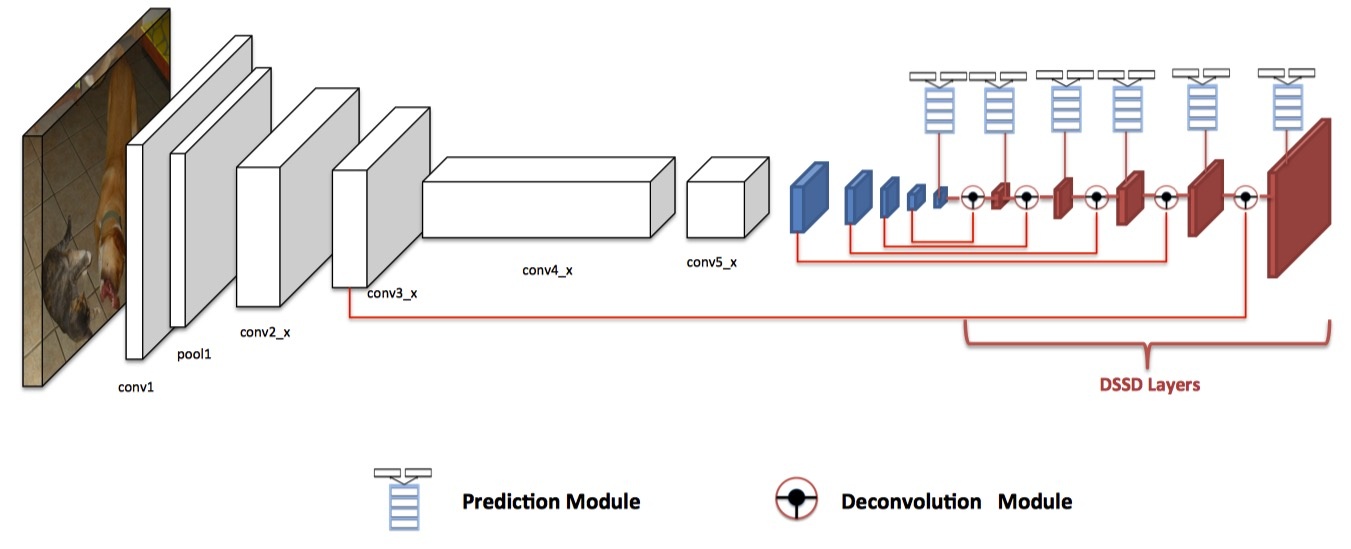
为了在检测中包含更多的高层次上下文,我们将prediction module转移到在原始SSD设置之后放置的一系列去卷积层中,有效地制作了非对称沙漏网络结构。
添加额外的去卷积层,以连续增加feature maps layers的分辨率。为了加强特征,我们采用了沙漏模型中“跳跃连接”的想法。
尽管沙漏模型在编码器和解码器阶段均包含对称层,但由于两个原因,我们使解码器阶段非常浅。
Deconvolution Module
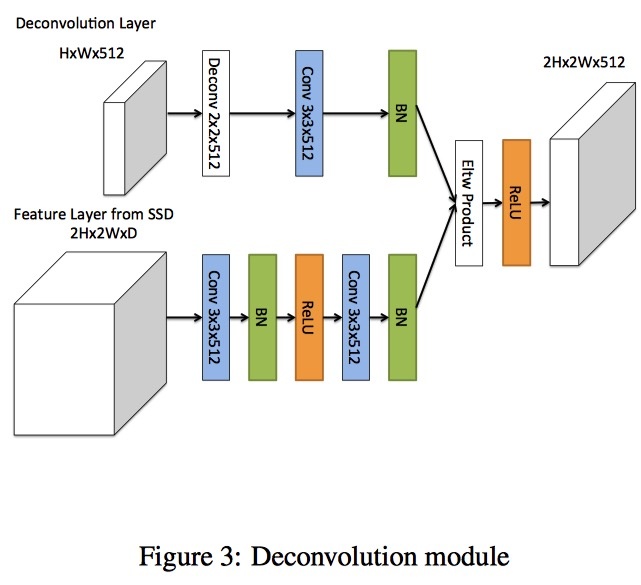
为了帮助整合早期特征图和去卷积层的信息,我们引入了一个去卷积模块,如图3所示。
首先,在每个卷积层之后添加BN层。
第二,我们使用学习的去卷积层代替双线性上采样。
最后,我们测试不同的组合方法:element-wise sum and element-wise product。
Traning
我们遵循与SSD相同的训练政策。
在原始SSD模型中,长宽比为2和3的boxes从实验中证明是有用的。为了了解训练数据(PASCAL VOC 2007和2012年 trainval)中边界框的纵横比, 我们以training box运行K-means聚类,以方格平方根为特征。我们从两个集群开始,如果错误可以提高20%以上,就会增加集群的数量。经过试验因此, 我们决定在每个预测层添加一个宽高比1.6,并使用(1.6, 2.0, 3.0)。
Experiments
PASCAL VOC2007 test detection results.

PASCAL 2012 test detection results.

COCO test-dev2015 detection results.
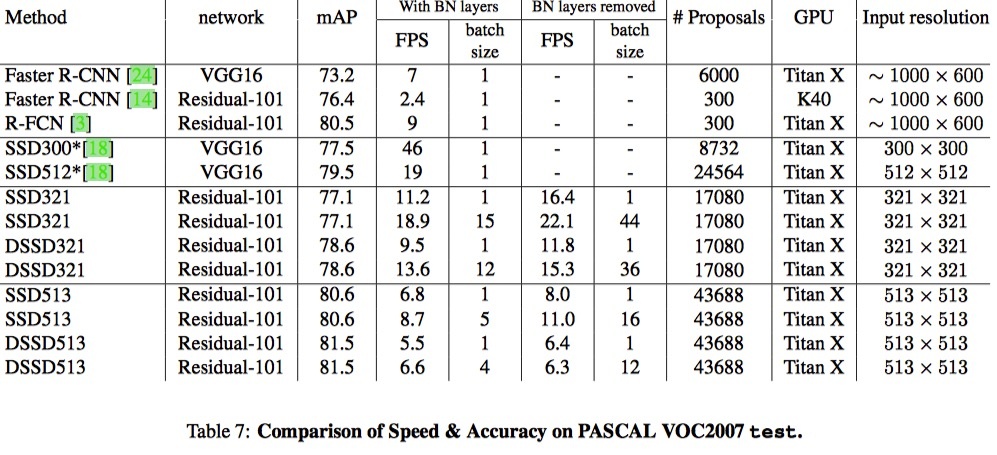
Comparison of Speed & Accuracy on PASCAL VOC2007 test.
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







