GAN过程可视化(toy)
GAN(生成对抗网络)的结果往往是观察生成的图片的质量,肉眼可以直接辨别好坏但是为了提高效率各位大佬利用inception_score作为 评判GAN生成质量的好坏。我们今天用一个GAN实验的toy大致说明设计的GAN模型的收敛和实际效果。
GAN过程可视化toy对于判断一个模型的可行性是一个较好的指示实验。我们今天做的toy实验在离散图的基础上考验GAN的生成能力,对于 inception_score的评判GAN生成图片的质量评分我们会单独做一个博客展示。
Toy实验准备
我们首先创造让GAN学习到的离散点分布,这一块采用指定的均值和协方差生成数据作为离散点数据,先上这一块实现代码:
def gmm_sample(num_samples, mix_coeffs, mean, cov):
z = np.random.multinomial(num_samples, mix_coeffs)
samples = np.zeros(shape=[num_samples, len(mean[0])])
i_start = 0
for i in range(len(mix_coeffs)):
i_end = i_start + z[i]
samples[i_start:i_end, :] = np.random.multivariate_normal(
mean=np.array(mean)[i, :],
cov=np.diag(np.array(cov)[i, :]),
size=z[i])
i_start = i_end
return samples
我们这里用到的均值和协方差生成的数据为一个近似圆形的离散图,实现的mix_coeffs, mean, cov的参数我选择的是:
mix_coeffs=(0.5, 0.5)
mean=((0.0, 0.0), (1.0, 1.0))
cov=((0.1, 0.1), (0.1, 0.1))
这样的取值可以达到数据点的可以实现我们想要的结果,我们打印一下得到的散点图的效果,当然大家可以根据自己的需要创造自己希望 GAN学习的散点分布。
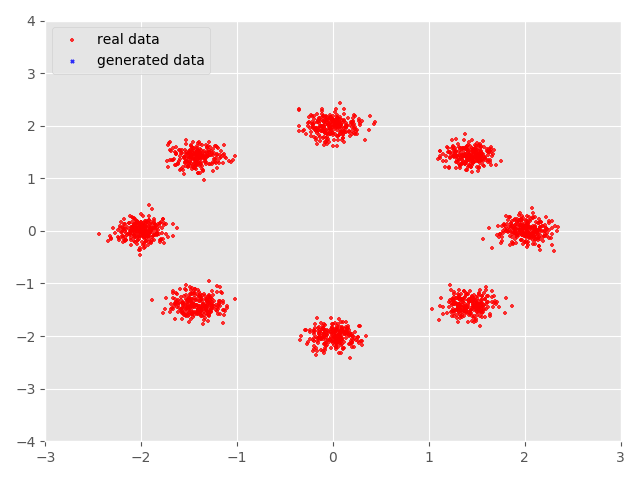
我们得到自己想要GAN学习的数据后就要实现怎么让GAN学习到这样的分布?
创造GAN模型
在之前的博客中我们有说过怎样实现GAN模型的搭建,我们这里的数据仅仅是一些离散数据点相对于庞大的图片数据,我们的数据点实际上 是不大的,这样在GAN设计上我们不必把神经网络搭的太深(因为没有这个必要)。我们仅仅需要linear就可以实现我们这次实验的目的了, 所以本实验不必使用高配置的电脑在一般的笔记本上就可以实现。
我们来看看我们的模型:
def _build_model(self):
# This defines the generator network - it takes samples from a noise
# distribution as input, and passes them through an MLP.
with tf.variable_scope('generator'):
self.z = tf.placeholder(tf.float32, shape=[None, self.num_z])
self.g = self._create_generator(self.z, self.hidden_size)
self.x = tf.placeholder(tf.float32, shape=[None, 2])
# The discriminator tries to tell the difference between samples from the
# true data distribution (self.x) and the generated samples (self.z).
#
# Here we create two copies of the discriminator network (that share parameters),
# as you cannot use the same network with different inputs in TensorFlow.
with tf.variable_scope('discriminator') as scope:
self.d_x = self._create_discriminator(self.x, self.hidden_size)
scope.reuse_variables()
self.d_g = self._create_discriminator(self.g, self.hidden_size)
# Define the loss for discriminator and generator networks (see the original
# paper for details), and create optimizers for both
self.d_loss = -tf.reduce_mean(tf.log(self.d_x) + tf.log(1-self.d_g))
self.g_loss = -tf.reduce_mean(tf.log(self.d_g))
self.d_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,
scope='discriminator')
self.g_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,
scope='generator')
self.d_opt = self._create_optimizer(self.d_loss, self.d_params,
self.learning_rate)
self.g_opt = self._create_optimizer(self.g_loss, self.g_params,
self.learning_rate)
上述模型的大致框架,生成器和判别器的实现我们用简单的线性神经网络就足够了,优化器选择比较有效率的AdamOptimizer:
def _create_generator(self, input, h_dim):
hidden = tf.nn.relu(linear(input, h_dim, 'g_hidden1'))
hidden = tf.nn.relu(linear(hidden, h_dim, 'g_hidden2'))
out = linear(hidden, 2, scope='g_out')
return out
def _create_discriminator(self, input, h_dim):
hidden = tf.nn.relu(linear(input, h_dim, 'd_hidden1', ))
hidden = tf.nn.relu(linear(hidden, h_dim, 'd_hidden2'))
out = tf.nn.sigmoid(linear(hidden, 1, scope='d_out'))
return out
def _create_optimizer(self, loss, var_list, initial_learning_rate):
return tf.train.AdamOptimizer(initial_learning_rate,
beta1=0.5).minimize(loss, var_list=var_list)
这里的生成器由于是生成的是二维离散点数据,所以我们的输出是二维的,判别器通过sigmoid得到概率值这样就实现了模型的搭建。
对于placeholder的值,对于self.z传入噪声,self.x为我们的实际数据点。
对于损失函数的设计,由于本实验仅仅是对传统GAN模型的验证,我们采用传统GAN的损失函数:
self.d_loss = -tf.reduce_mean(tf.log(self.d_x) + tf.log(1-self.d_g))
self.g_loss = -tf.reduce_mean(tf.log(self.d_g))
具体的损失函数的设计我们在之前的博客有详细说明, 这里也就不展开了。
模型整体搭建完以后就可以传入值进行训练了,那就开始训练模型:
def fit(self):
plt.ion()
if (not hasattr(self, 'epoch')) or self.epoch == 0:
self._init()
with self.tf_graph.as_default():
self._build_model()
self.tf_session.run(tf.global_variables_initializer())
while self.epoch < self.num_epochs:
# update discriminator
x = gmm_sample(self.batch_size, self.mix_coeffs, self.mean, self.cov)
z = np.random.normal(0.0, 1.0, [self.batch_size, self.num_z])
d_x, d_loss, _ = self.tf_session.run(
[self.d_x, self.d_loss, self.d_opt],
feed_dict={self.x: np.reshape(x, [self.batch_size, 2]),
self.z: np.reshape(z, [self.batch_size, self.num_z]),
})
# update generator
z = np.random.normal(0.0, 1.0, [self.batch_size, self.num_z])
g_loss, _ = self.tf_session.run(
[self.g_loss, self.g_opt],
feed_dict={self.z: np.reshape(z, [self.batch_size, self.num_z])})
if np.mod(self.epoch, 200) == 0:
print("Epoch: [%4d/%4d] ,"
" d_loss: %.8f, g_loss: %.8f" % (self.epoch, self.num_epochs,
d_loss, g_loss))
self.epoch += 1
if np.mod(self.epoch, 50) == 0:
x = gmm_sample(1000, self.mix_coeffs, self.mean, self.cov)
g = self.generate(num_samples=1000)
plt.cla()
plt.scatter(x[:, 0], x[:, 1], s=5, marker='+', color='r',
alpha=0.8, label='real data')
plt.scatter(g[:, 0], g[:, 1], s=5, marker='x', color='b',
alpha=0.8, label='generated data')
plt.legend(loc='upper left')
plt.xlim(-3, 3)
plt.ylim(-4, 4)
plt.draw()
plt.pause(0.01)
if self.epoch % self.disp_freq == 0:
self.display(num_samples=1000)
generate_animation(self.result_dir + '/' + self.model_name, self.num_epochs//1000)
plt.show()
plt.ioff()
这里的epoch我们是一步步训练,所以这里去的epoch是比较大的,一般要在50000以上吧,当然这一部分根据实际情况来。为了方便观察 我采用实时打印出训练数据来,这就用到了matplotlib中的plt.io可以做到实时显示结果,这一步骤在正真的应用上还是比较普遍的。我们 这里50步一打印。由于实际生成器得到的数据还要经过一定的加工才能作为图片打印的数据,我们只是简单的数据做处理。
def generate(self, num_samples=1000):
zs = np.random.normal(0.0, 1.0, [num_samples, self.num_z])
g = np.zeros([num_samples, 2])
batches = make_batches(num_samples, self.batch_size)
for batch_idx, (batch_start, batch_end) in enumerate(batches):
g[batch_start:batch_end] = self.tf_session.run(
self.g,
feed_dict={
self.z: np.reshape(zs[batch_start:batch_end],
[batch_end - batch_start, self.num_z])
}
)
return g
这里是为了实现在训练batch_size下得到输出数据。到了这一步本试验的核心部分已经说明完毕了,当然还有一部分代码没有分析,那些 都是比较基础的一部分了,这里就不展开说明了,比如显示图片和保存图片成gif这些在实际应用中大家只要经常使用都是可以掌握的。 对于plt的应用,我有可能会写一篇博客简单说说使用的技巧。接下来我们看看实验的结果。
实验结果
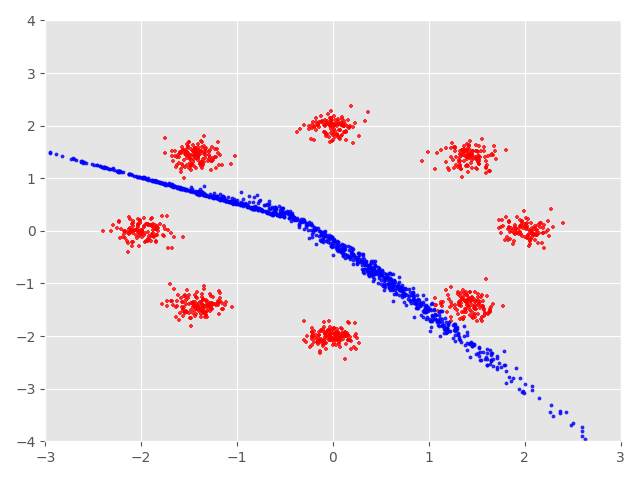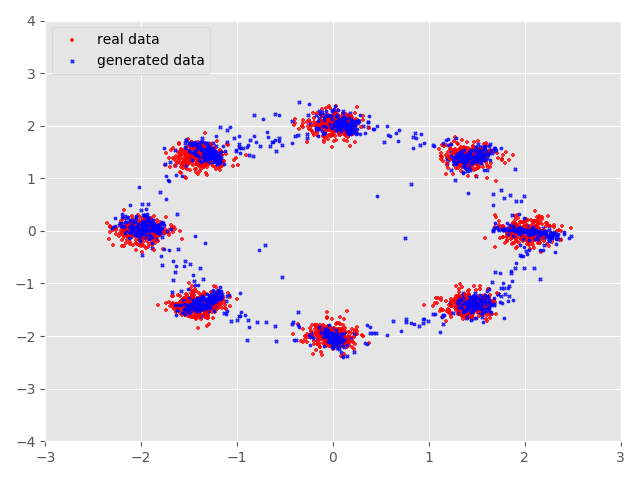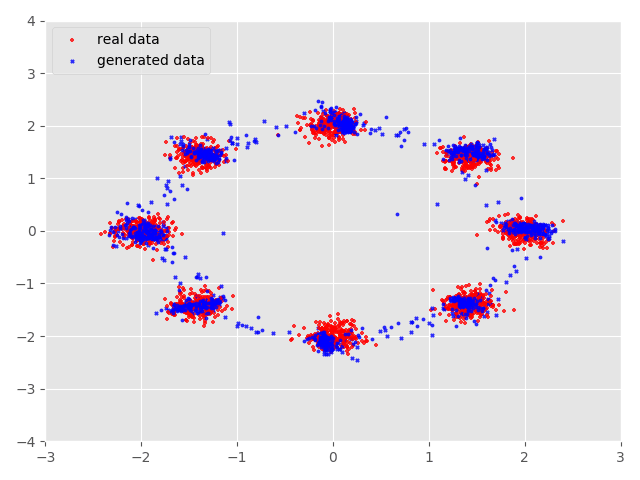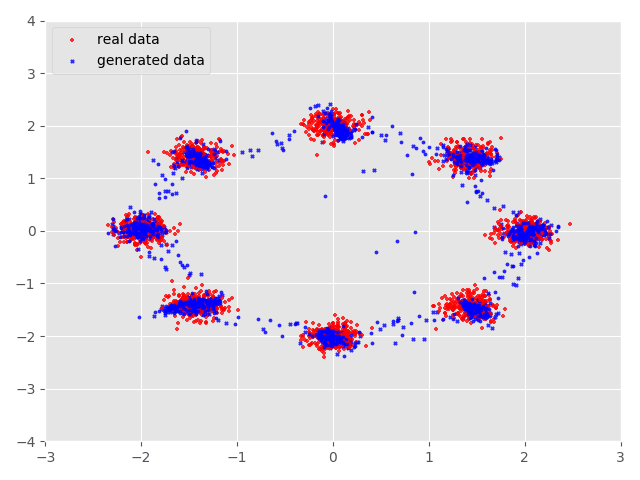
我们先看看整理过的实验数据,下图展示了经过45000epoch后GAN生成的效果图,其中蓝色数据点是生成数据,红色数据点是实际数据。
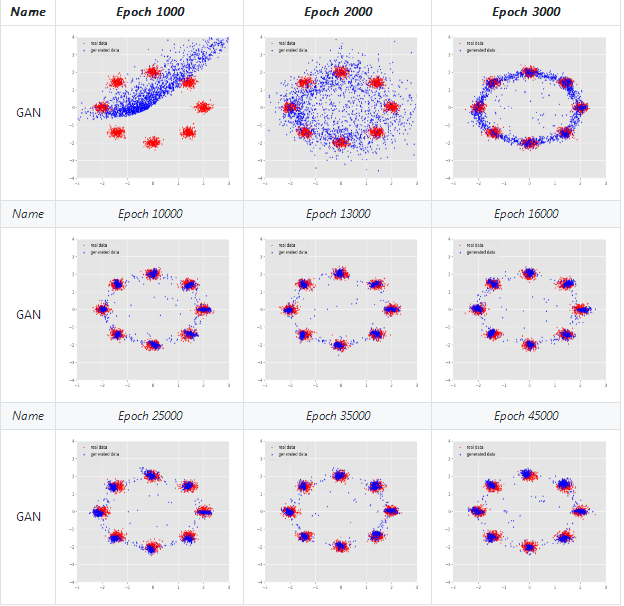
我们可以看到在刚开始训练的时候生成的数据点与真实数据分布还是有很大不同的但是经过不断的训练生成数据不断地与实际数据相吻合 到了10000epoch后生成数据便基本上和实际数据相互重合了,但是在一些数据点上还是不能很好的重合。这与GAN自身存在的问题还是有一定 联系的。
最后我们看看训练输出的过程演示:
本实验完整代码see_GANs
如果感觉不错记得在github和微博上点个关注!
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







