GAN代码的搭建(3)
在上一篇文章GAN的网络框架搭建好了,本文将对GAN文章中的损失函数代码实现加以说明。
很多机器学习的算法的核心就是在损失函数的设计山,当然GAN的实现的核心也是离不开损失函数的作用。最大最小博弈就是损失函数的设计理念,我们要怎 么用代码去实现呢?首先我们看看GAN的损失函数再来想想如何去实现。
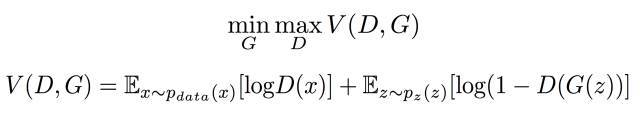
D的目的是增大目标函数V,所以在实际训练过程中我们只需要在V前面整体加上一个负号就行,这样最大化就可以转化为最小V一般的优化器都是最小化损失 函数所以在操作上我们要将最大改为最小。这样我们就可以实现判别器D的损失函数的设计了。再看看G的损失函数,我们观察目标函数,第一项中是不含G的 所以我们可以不考虑第一项,仅仅对第二项讨论。最小化第二项就相当于下面操作:
![]()
好了,到此我们的两个损失函数都设计好了,接下来只要代码实现就好了,上代码:
""" Loss Function """
# output of D for real images, D_real((64,1),介于(0,1)),D_real_logits未经历
# 过sigmoid,_临时存储net(64,1024)
D_real, D_real_logits, _ = self.discriminator(self.inputs, is_training=True, reuse=False)
# output of D for fake images G为由噪声z(64,62)生成的图片数据(64,28,28,1)
G = self.generator(self.z, is_training=True, reuse=False)
# D_fake((64,1),介于(0,1)),D_fake_logits未经历过sigmoid,_临时存储net(64,1024),
# 送入鉴别器的是G生成的假的数据
D_fake, D_fake_logits, _ = self.discriminator(G, is_training=True, reuse=True)
# get loss for discriminator
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=D_real_logits,
labels=tf.ones_like(D_real)))
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits,
labels=tf.zeros_like(D_fake)))
#d_loss为生成器和鉴别器传出的loss之和
self.d_loss = d_loss_real + d_loss_fake
# get loss for generator
#g_loss=-log(sigmoid(D_fake_logits))等价于g_loss=-log(D(G(z))
self.g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=D_fake_logits,
labels=tf.ones_like(D_fake)))
""" Training """
# divide trainable variables into a group for D and a group for G
t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if 'd_' in var.name]
g_vars = [var for var in t_vars if 'g_' in var.name]
# optimizers 优化器用于减小损失函数loss,采用Adam优化器
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
self.d_optim = tf.train.AdamOptimizer(self.learning_rate, beta1=self.beta1) \
.minimize(self.d_loss, var_list=d_vars)
self.g_optim = tf.train.AdamOptimizer(self.learning_rate*5, beta1=self.beta1) \
.minimize(self.g_loss, var_list=g_vars)
优化器选择的是Adam优化器,当然也可以选择其它的,根据实际实验更改。基本上到这里损失函数的设计上已经完成了,tensorflow中提供了可视化的好 工具tensorboard所以最好在写程序的时候考虑到就可以在tensorboard上观察到网络参数的变化情况。这里我就不详细展开怎么加了,具体的我还会写一 篇关于如何使用tensorboard的文章。
损失函数已经实现了,接下来就是如何在训练中训练就行了。训练和实验结果我们下次再说,今天就写到这里。
我的GANs的完整代码:
大家感觉可以就在github项目上点一下关注,哈哈
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!

扫码打赏一下,你说多少就多少


打开微信扫一扫,即可进行扫码打赏哦







