CycleGAN介绍
CycleGAN是涉及到一定风格变换的GAN模型,可以实现两个场景的转化。

CycleGAN的问世将GAN的生成上的应用又提高到了一个阶段,已经可以做到风格上的变换实现。一个普通的
GAN只有一个生成器和一个判别起。而在这篇文章里,分别有两个生成器和判别器。一个生成器将X域的图片转换成Y域的图片(用G表示),而另一个生成器
做相反的事情,用F表示。而两个判别器Dx和Dy试图分辨两个域中真假图片。(这里假图片指的是从真照片transform来的)。这里的Cycle的意思就是能从X转
换到Y,然后再从Y转换到X,最后的结果应该和输入相似。这里他们用最后输出和输入的L1距离来作为另外的惩罚项。数学表达式为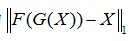 和
和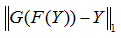 足够的小。这个惩罚项防止了mode collapse的问题。如果没有这个cycle consistency项,网络会
输出更真实的图片,但是无论什么输入,都会是一样的输出。而如果加了cycle consistency,一样的输出会导致cycle consistency的直接失败。所以
这规定了在经过了变换之后的图片不仅需要真实,且包含原本图片的信息。上述描述可参考下图理解:
足够的小。这个惩罚项防止了mode collapse的问题。如果没有这个cycle consistency项,网络会
输出更真实的图片,但是无论什么输入,都会是一样的输出。而如果加了cycle consistency,一样的输出会导致cycle consistency的直接失败。所以
这规定了在经过了变换之后的图片不仅需要真实,且包含原本图片的信息。上述描述可参考下图理解:
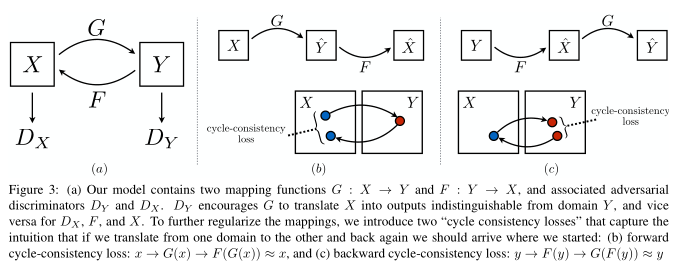
Unpaired的方法通过对源域图像进行两步变换:首先尝试将其映射到目标域,然后返回源域得到二次生成图像,从而消除了在目标域中图像配对的要求。使 用生成器(generator)网络将图像映射到目标域,并且通过匹配生成器与鉴别器(discriminator),能提高该生成图像的质量。对抗的思想可参考原 文:从理论上讲,对抗训练可以学习和产生与目标域Y和X相同分布的输出,即映射G和F。然而,在足够大的样本容量下,网络可以将相同的输入图像集合映 射到目标域中图像的任何随机排列,其中任何学习的映射可以归纳出与目标分布匹配的输出分布。因此,单独的对抗损失Loss不能保证学习函数可以将单个 输入Xi映射到期望的输出Yi。为了规范模型,作者介绍了循环一致性的约束条件:如果我们从源分布转换为目标分布,然后再次转换回源分布,那么应该可 以从源分布中获取样本。下图形象说明了上述描述:
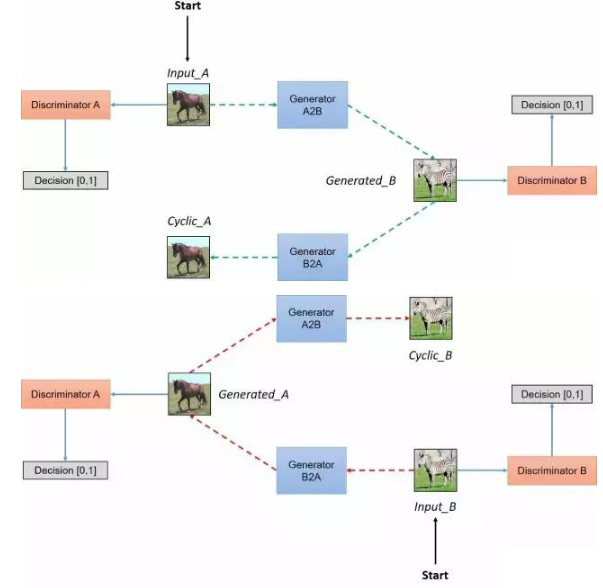
在一个配对数据集中,每张图像,如imgA,人为地映射到目标域中的某个图像,如imgB,以便两者共享各种特征。从imgA到imgB的特征可用于其相对应的 映射过程中,即从imgB到imgA的特征。配对一般是为了使输入和输出共享一些共同的特征。当一张图像从一个域到另一个域时,该映射定义了一种有意义的 变换。因此,当我们配对数据集时,生成器必须从域DiscriminatorA中获得一个输入,例如inputA,并将该图像映射到输出图像,即GeneratorB,原始 图像必须与其映射对象相近。但是,我们在不配对的数据集中没有这个对象,也没有预先定义好的用于学习的有意义转换,所以我们将要创建它。我们需要 确保输入图像和生成图像之间存在一些有意义的关联。在文章中作者试图通过生成器将输入图像(inputA)从域DA映射到目标域DB中,转换成对应图像。但 是为了确保这些图像之间存在有意义的关系,它们必须共享一些特征,这些特征可用于将此输出图像映射回输入图像,因此必须有另一个生成器能将此输出图 像映射回原始域。因此,我们需要定义inputA和GeneratorB之间有意义的映射。
我的理解是该模型通过从域DA获取输入图像,该输入图像被传递到第一个生成器GeneratorA→B,其任务是将来自域DA的给定图像转换到目标域DB中的图像。 然后这个新生成的图像被传递到另一个生成器GeneratorB→A,其任务是在原始域DA转换回图像CyclicA,这里可以和自编码器作对比。这个输出图像必须与 原始输入图像相似,用来定义非配对数据集中原来不存在的有意义映射。
如上图所示,两个输入被传递到对应的鉴别器(一个是对应于该域的原始图像,另一个是通过生成器产生的图像),并且鉴别器的任务是区分它们,识别出生 成器输出的生成图像,并拒绝此生成图像。生成器想要确保这些图像被鉴别器接受,所以它将尝试生成与DB类中原始图像非常接近的新图像。事实上,在生成 器分布与所需分布相同时,生成器和鉴别器之间实现了纳什均衡(Nash equilibrium)。
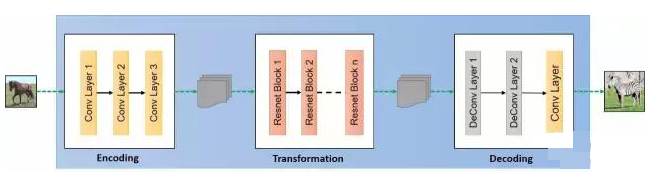
生成器的结构和实现如下图所示:
小结:本文对CycleGAN做个简单的分析,CycleGAN对GAN模型实现风格转换开创了先河,我们要理解GAN在实现image2image的可操作性。
谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







