GAN存在的问题
GAN在实际应用中是否存在问题呢?答案是肯定的,本文将阐述GAN的问题到底出在哪里。
传统GAN在自提出以后最大的冲击就是WGAN的提出,WGAN也引起了GAN的作者Ian Goodfellow的高度关注,并且在各大论坛转载分享建议大家一起学习。 为什么WGAN能这么的火热呢?这就要归结于WGAN作者Martin Arjovsky强大的数学功底。作者利用严谨的数学公式推证了GAN存在的两大问题。第一个就是 传统GAN在判别器训练的越好的情况下,生成器越容易出现梯度消失情况;第二个问题就是传统GAN的collapse mode,模型崩塌或者称为多样性不足的造成 原因。在严谨的数学公式推证下连GAN的作者也正视了这个问题,鼓励大家一起学习WGAN。
WGAN算是有两篇文章,第一篇是说明GAN存在的问题,第二篇 是提出新算法改进。坦白的说这两篇论文的公式多的有点离谱了,但是这么经典的东西还是要花时间去消化的。根据已有知识和各大论坛的拜读以及文章的理 解我算是用已有的数学能力把WGAN前作中的公式做了梳理和理解,具体推导在附录中。
GAN存在的第一个问题
我们来简单回顾一下,GAN在判别器D训练到最优的时候,生成器C(G)为:
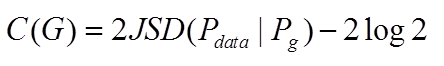
其中
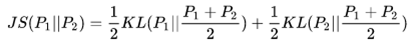
我们来简单计算一下,在两个分布不相同时,即
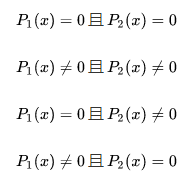
第一项和第二项的分布没有参考价值,分析第三第四项,以第三项分析代入计算我们可以得到:
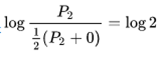
此时JS散度衡为log2,也就是说C(G)=0,这就导致了GAN在判别器训练的越好的情况下,生成器越容易出现梯度消失情况。当然这时的条件是生成分布和真 实分布是不重合的。形象一点的话可以看看下图:

GAN存在的第二个问题
我们再通过公式简单分析一下GAN的第二个问题,在GAN的最优解中有KL散度一项,我们拿出来分析一下
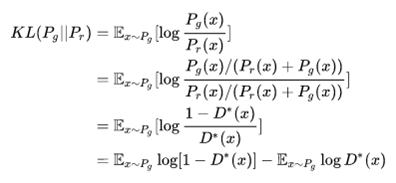
通过移项可以得到
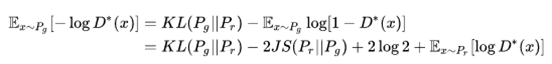
公式中第一项是减小真实数据与生成数据的分布,第二项是增大真实数据与生成数据的分布。这样一拉一收将会导致训练不稳定,生成器到底是增大还是减小 呢?我们可以做个分析
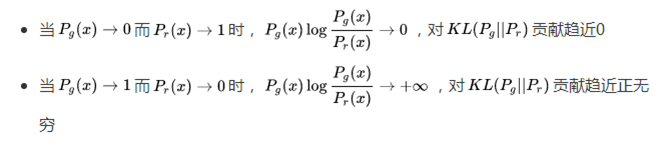
在判别器的作用下生成器为了得到最小的惩罚,将会生成更倾向于真实的数据不会冒险生成与已有真实分布不同的数据。我们用一张图展示一下,下图描述了 GAN生成多样性不足的原因:
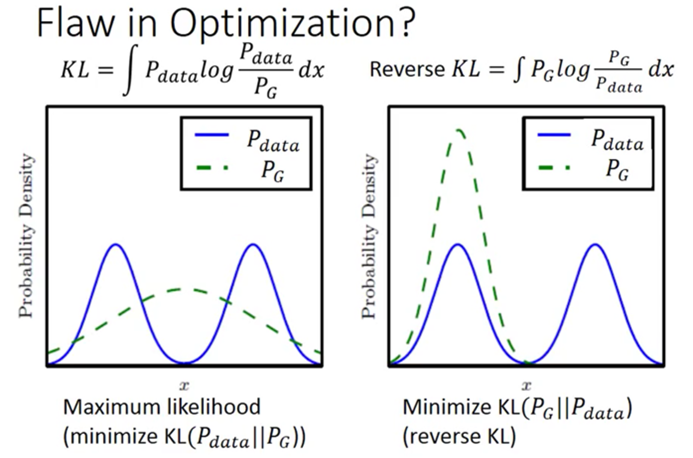
由图我们可以得到,生成器更倾向于生成右侧情形的数据,不敢冒险越过雷池去尝试第一种情况,这就是collapse mode的一种解释。
我们再一起缕一遍,在传统GAN文章中有推导过判别器最优解和生成器的最优解,我之前报告上也在附录中推导过。正是由于对生成器的最优解的理想化造成 大家陷入对模型的信赖上(大多数学者不相信也不行啊)。在生成器最优解的推导时,理想下的JS散度为0,但是这个JS会为0吗?作者提出一旦数据上升到 高维情况下JS散度将不可能为0,而是趋近一个常数log2,这就导致G的目标函数值为0从而造成梯度消失情况,也就是GAN的第一种问题。在调整损失函数后 用G的最优解和KL以及JS散度做变换后出现KL与JS之间的分布矛盾的现象,这样在生成器生成数据时,生成数据分布和原始数据分布在两种不同衡量度下产生 矛盾,最后的结果是G为了不受大的惩罚更愿意犯惩罚度小的错误,经过不断训练后,这种错误将会导致G生成的数据缺乏多样性从而导致出现collapse mode。
WGAN论文洋洋洒洒的用了17张纸推证这两个问题,密密麻麻的公式让人望尘莫及。在阐述上的严谨确实说明了GAN的问题造成原因,作者通过重置训练阶段的 weight值验证结论的正确性,从实验的结果上确实可以得到论文的推证也是没问题的。
那如何改进这两种问题呢?哈哈,其实已经有很多文章在解决这两个问题上做了很好的效果。本文只简单说说有哪些方法可以做到对问题的改进。
首先是对梯度消失问题的简单解决,就是在生成数据上增加高维噪声让生成分布与真实分布存在一定的重合这样就避免了JS为log2的悲剧,我们可以由下图 简单看一下实现方法:

还有一些方法可以应用,我就简单罗列一下:
1.有条件的控制输入z,比如让z为encoder(z)
2.minibatch discrimination,让GAN的判别网络D进行判别时,不要基于单个样本,而是基于一个minibatch的一批样本。
3.更改损失函数(难度很大)
4.用判别器去学到的feature来做辅助,让G生成数据的时候尽可能的去匹配D的一些feature的统计特征。
好了这一部分就简单写到这里,具体的改进方法我们接下来的文章还会去写的。接下来是附录,可选择性参考。
附录


谢谢观看,希望对您有所帮助,欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







