传统GAN的介绍
生成对抗网络自2014年提出来以后持续火热,今天我们一起来看看这个由GoodFellow提出来的GAN的思想
GAN是由Ian Goodfellow在2014年写的《Generative Adversarial Nets》文章中提出的最新的思想。 对于GAN我认为是个十分有意义的模型颠覆了我对计算机的理解,下图对框架做了描述:
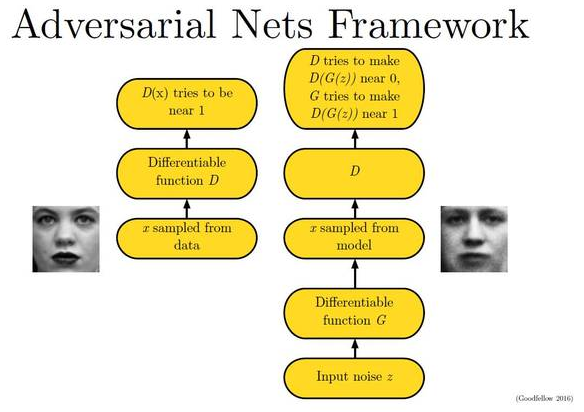
有一个比方很贴切的描述Generator和Discriminator,G就是一个生成模型,类似于卖假货的,一个劲儿地学习如何骗过D。而D则是一个判别模型,类似 于警察叔叔,一个劲儿地学习如何分辨出G的骗人技巧。如此这般,随着D的鉴别技巧的越来越牛,G的骗人技巧也是越来越纯熟。一个造假一流的G,就是 我们想要的生成模型。下图描述了GAN的生成模型:

如图所示,生成器把噪声数据 z(也就是我们说的假数据)通过生成模型 G,伪装成了真实数据 x。(当然,因为 GAN 依旧是一个神经网络,你的生成模型 需要是可微的(differentiable)). 训练的过程也比较直观,可以选择任何类 SGD 的方法(因为G和D两个竞争者都是可微的网络)。并且你要同时训练两 组数据:一组真实的训练数据和一组由骗子G生成的数据。当然,也可以一组训练每跑一次时,另一组则跑 K 次,这样可以防止其中一个跟不上节奏。对于 最小最大博弈由下图展示:

在这里,J(D) 代表判别网络(也就是警察D)的目标函数—一个交叉熵(cross entropy)函数。其中左边部分表示 D 判断出 x 是真 x 的情况,右边部 分则表示D判别出的由生成网络G(也就是骗子)把噪音数据 z 给伪造出来的情况。同理,J(G) 就是代表生成网络的目标函数,它的目的是跟 D 反着干, 所以前面加了个负号(类似于一个 Jensen-Shannon(JS)距离的表达式)。这样就像两个人的零和博弈,一个想最大,另一个想最小。那么就要找到均衡点 (也就是纳什均衡)就是 J(D) 的鞍点(saddle point)。由下图可形象的展示出来:
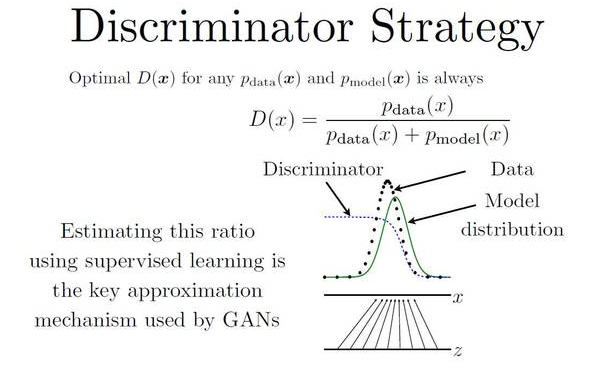
由图,我们手上有真实数据(黑色点,data)和模型生成的伪数据(绿色线,model distribution,是由我们的 z 映射过去的)(画成波峰的形式是 因为它们都代表着各自的分布,其中纵轴是分布,横轴是我们的 x)。而我们要学习的 D 就是那条蓝色的点线,这条线的目的是把融在一起的 data 和 model 分布给区分开。写成公式就是 data 和 model 分布相加做分母,分子则是真实的 data 分布。我们最终要达到的效果是:D 无限接近于常数 1/2。换句话说就是要 Pmodel 和 Pdata 无限相似。这个时候,D分布再也没法分辨出真伪数据的区别了。这样就可以说模型训练出了一个炉火纯青的造 假者(生成模型)。结果就是下图的样子:
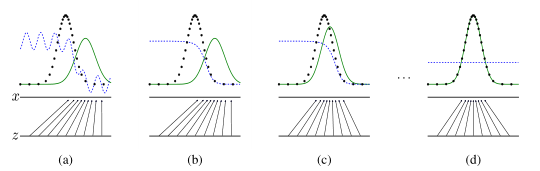
但是这样也会有新的问题,生成模型跟源数据拟合之后就没法再继续学习了(因为常数线 y = 1/2 求导永远为 0)。为了解决这个问题,除了把两者对抗 做成最小最大博弈,还可以把它写成非饱和(Non-Saturating)博弈:

由图中 G 自己的伪装成功率来表示自己的目标函数(不再是直接拿 J(D) 的负数)。这样的话,均衡就不再是由损失(loss)决定的了。J(D) 跟 J(G) 没有简单粗暴的相互绑定,就算在 D 完美了以后,G 还可以继续被优化。在应用上,这套 GAN 理论最火的构架是 DCGAN(深度卷积生成对抗网 络/Deep Convolutional Generative Adversarial Network)。这也就是我之前学的CNN的强化版本这就是一个反向的 CNN。
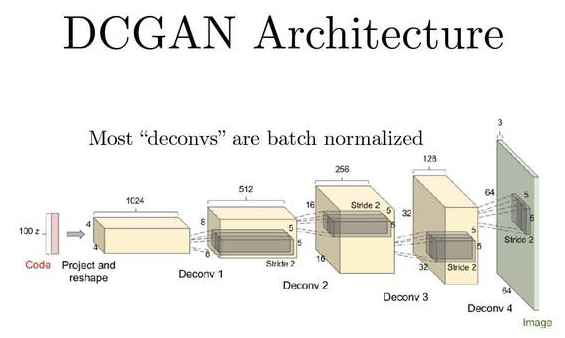
DCGAN目的是创造图片,其实就类似于把一组特征值慢慢恢复成一张图片。它与CNN的两者的比较就是:在每一个滤镜层,CNN是把大图片的重要特征提取出 来,一步一步地减小图片尺寸。而DCGAN是把小图片(小数组)的特征放大,并排列成新图片。这里,作为DCGAN的输入的最初的那组小数据就是我们刚刚讲 的噪声数据。
欢迎指正错误,欢迎一起讨论!!!

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







