MelGAN快速生成音频
谈到数据的生成,很多人都会想到利用生成对抗网络(GAN)去实现,这对于图像和视频这种较易于编码表示的数据是合适的。然而在实现音频的生成时,却是困难重重,首先音频具有较高的时间分辨率(通常至少为每秒16,000个样本),并且在不同时间尺度上存在具有短期和长期依赖性的结构。就目前基于GAN做音频生成的文章中,基本上都是生成出音频对应的中间形态-声谱图。本篇将对音频的后端生成进行分析,介绍MelGAN是如何通过梅尔谱图快速转换得到最终声音的。
论文引入
对原始音频进行建模是一个特别具有挑战性的问题,因为音频具有很高的时间分辨率,同时音频在时间尺度上是有前后依赖关系的。因此,目前大多数方法不是直接对原始时间音频建模,而是通过对原始音频信号进行较低分辨率表示后再进行建模。选择这样的表示形式比使用原始音频更容易建模,同时也保留足够的信息再次转换回音频。这种低分辨率的表示我们称之为音频的中间形式,目前主流的中间形式表达有两种,对齐的语言特征[1]和Mel频谱图[2]。有了音频的中间形式,那么对音频建模就可以转换为$音频 \to 中间形式 \to 音频$。
音频转换到中间形式相对来说是比较容易的,拿Mel频谱图的转换来说,首先对原始音频文件进行采样,采样速率视实际音频而定,对采样后的信号进行短时傅里叶变换,即在傅里叶变换过程中,使用时间窗口函数与源信号相乘,通过窗函数的滑动得到一系列傅里叶变换的结果,其中快速傅里叶变换的点数和窗函数每次滑动的大小也是人为设定,进而得到其线性振幅谱,然后利用梅尔滤波器组就可以得到梅尔频谱图,其中梅尔滤波器组的个数视实际而定,最后还可以通过对数运算将线性谱转换为对数谱,这个对数谱图可由图1表示。

图1.音频的对数谱图表示
由音频的中间形式转换为原始音频是一项很大的挑战,不过目前倒是已经有一些方法去实现这个转换。这个转换过程可分为三大家族:纯信号处理技术,自回归和非自回归神经网络。
纯信号处理:较早的Griffin-Lim算法[3]使人们可以有效地将STFT序列解码回时间信号,而代价是要引入了伪像。WORLD声码器[4]引入了一种中间类表示形式,专门针对基于类似于mel频谱图的特征的语音建模而设计。WORLD声码器与专用信号处理算法配对,以将中间表示映射回原始音频。这些纯信号处理方法的主要问题是,从中间特征到音频的映射通常会引入明显的伪像。
基于自回归神经网络模型:WaveNet[1]是一种完全卷积的自回归序列模型,可生成高度逼真的语音样本,该样本与原始音频在时间保持对齐为条件,同时它还能够生成高质量的无条件语音和音乐样本。SampleRNN[5]是一种执行无条件波形生成的替代架构,该架构使用多尺度递归神经网络以不同的时间分辨率显式建模原始音频。WaveRNN[6]是一种基于简单单层递归神经网络的更快的自回归模型。然而,由于这些自回归模型必须依次生成音频样本,因此对这些模型的推论本质上是缓慢且效率低下的,所以自回归模型通常不适合实时应用。
基于非自回归神经网络模型:并行WaveNet[7]和Clarinet[8]将经过训练的自回归解码器提炼成基于流的蒸馏模型。WaveGlow[9]是一种非常高容量的生成流,由12个耦合和12个可逆$1 \times 1$卷积组成,每个耦合层由8层膨胀卷积的堆栈组成。然而,这些基于非自回归模型的一大弊病就是训练成本太高,往往需要耗费长时间在训练上。
GAN在数据生成上已经取得了很大的进展,尽管它们在计算机视觉方面取得了巨大的成功,但在使用GAN进行音频建模方面,并没有多大的进展。目前基于GAN对音频生成的文章中,大多数是对于音频表示为中间形式就戛然而至了,完全由GAN一步到位生成音频样本的到目前还没有。本篇要介绍的MelGAN打破了这一僵局的同时,还大大提升了音频建模的速度,总结一下MelGAN的优势:
- MelGAN是一种非自回归前馈卷积架构,是第一个由GAN去实现原始音频的生成,在没有额外的蒸馏和感知损失的引入下仍能产生高质量的语音合成模型。
- MelGAN解码器可替代自回归模型,以生成原始音频。
- MelGAN的速度明显快于其他Mel谱图转换到音频的方法,在保证音频质量没有明显下降的情况下比迄今为止最快的可用模型快10倍。
模型总览
MelGAN是基于GAN实现的,整体结构不难理解就是由生成器和判别器组成,整体结构如图2所示:
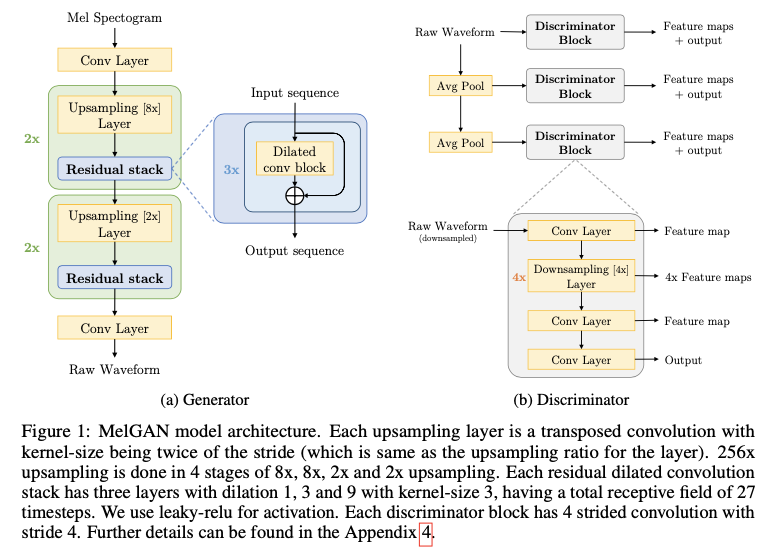
图2.MelGAN整体架构
生成器的输入是Mel谱图,经过一层Conv层后送到上采样阶段,经过两次$8 \times$后再经过两次$2 \times$,每次上采样中嵌套残差模块,具体的设计目的我们后面详细展开。最后经过一层conv层得到音频输出,由于音频的channel表示为1,所以最后一层的channel设为1。对于判别器,则是采用多尺度架构,也就是除了对原始音频做判别,还对原始音频做降频处理后再馈送到判别器下进行判别,这里的降频方式采用Avg pooling方式。判别器的内部模块设计主要是卷积层和下采样层得到,后续做详细展开。
生成器与判别器的设计
GAN的训练向来是不太稳定的,为了实现比较好的音频生成,作者也是在生成器和判别器的设计上下足了功夫。
生成器:
生成器的输入是声音的频谱图,输出是频谱图对应的音频,在实际处理音频时,文章采用的hop_length(帧移对应卷积中的stride也可以理解为连续帧分割长度)为256,所以Mel频谱图的时间分辨率比原始音频低256倍,所以在生成器的设计上要做到总共$256 \times$的上采样。与传统的GAN不同,MeilGAN生成器并没有使用全局噪声矢量作为输入,在实验中注意到,当额外的噪声馈送到生成器时,所产生的波形几乎没有感知差异。这是不合理的情况,因为由音频到Meil谱图的过程是个有损压缩过程,做逆映射的时候多少不能完全保真的还原。为了保持合理性,作者并没有将噪声馈送到生成器端。图3展示了生成器的详细设计结构:
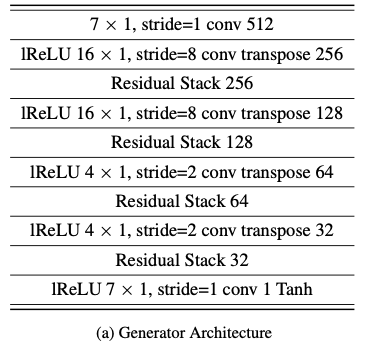
图3.MelGAN生成器的详细设计
为了增强音频在生成过程中的时间步长之间存在长程相关性,作者在上采样后加入了带有空洞卷积的残差块,以便每个后续层的时间远的输出激活具有明显的重叠输入。空洞卷积层的感受野随层数的增加而指数增加,能够有效地增加每个输出时间步长的感应野。相距较远的时间步长的感应野中存在较大的重叠,从而导致更好的远程相关性。残差块主要是3个空洞卷积块组成,每个空洞卷积块由两层卷积层组成。
GAN在做图像生成的时候常常伴有棋盘状伪影的出现,这个对应到音频生成中表现为可听到的高频嘶嘶声,为了改善这种”伪影”现象,文章通过仔细选择反卷积层的内核大小和步幅来解决此问题,使用内核的大小为跨度的倍数(如果步长为8,则内核大小则为16),为了防止空洞卷积层导致的”伪影”,模型确保空洞随核大小的增长而增长,从而使堆栈的接受域看起来像一个完全平衡且对称的树,核大小则作为分支因子。图4给出了空洞残差块的详细设计结构:
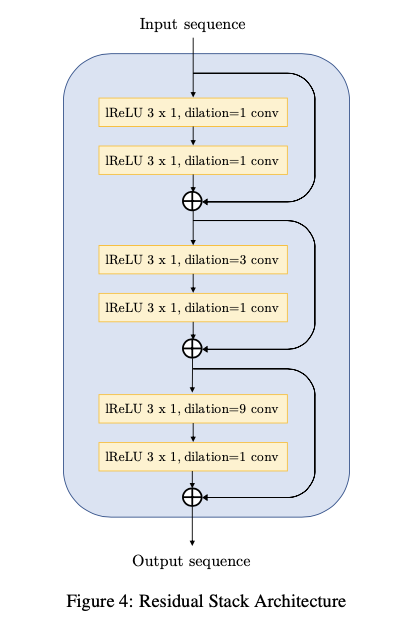
图4.MelGAN生成器中空洞残差块的详细设计
最后说一下生成器中的归一化的使用,在GAN做图像生成过程中,如果是随机噪声到图像的生成任务下我们常常使用Batch Normalization,在做图像到图像转换的任务下我们常使用Instance Normalization。由Mel谱图到音频的转换过程更像是在做转换任务,但是,在生成音频的情况下,实验发现Instance Normalization会冲走重要的音高信息,使音频听起来具有金属感。那使用谱归一化呢?当在发生器上应用频谱归一化时,同样得到了较差的结果。 作者认为,对判别器的强烈Lipshitz约束会影响用于训练生成器的特征匹配目标。在所有可用的归一化技术中,最后发现权重归一化[10]效果最好,因为它不会限制判别器的空间或对激活进行归一化。它只是通过将权重矢量的比例从方向上解耦来简单地重新配置权重矩阵,以具有更好的训练动态。因此,文章在生成器的所有层中使用权重归一化。
判别器:
为了实现判别器可以学习音频不同频率范围的特征,文章设计的判别器采用多尺度,具有3个判别器($D_1,D_2,D_2$)的多尺度架构,这些判别器具有相同的网络结构,但在不同的音频规模上运行。$D_1$以原始音频的规模运行,而$D_2,D_3$分别以降频2倍和4倍的原始音频运行,这个多尺度是通过上一尺度下步长为2的平均池化下采样得到的,且内核大小都是3。
判别器的架构利用分组卷积允许使用较大的内核(文章用的是$41 \times 41$),同时保持较小的参数数量。由于判别器损耗是在每个内核窗口非常大的重叠窗口上计算,因此,MelGAN模型学会了在各个音块之间保持相干性。文章选择基于分组卷积的判别器,也是为了保证捕获音频中的高频结构,而且具有较少的参数,运行速度更快还可以应用于可变长度的音频序列。与生成器类似,在判别器的所有层中使用权重归一化。判别器的详细结构如图5所示。

图5.MelGAN判别器的详细设计
损失函数:
损失函数上,文章采用了Hinge loss作为生成对抗网络的损失:
\[\min_{D_k} \mathbb E_x[min(0, 1-D_k(x))]+\mathbb E_{s,z}[min(0, 1+D_k(G(s,z)))],\forall k = 1,2,3\] \[\min_G \mathbb E_{s,z}[\sum_{k=1,2,3} -D_k(G(s,z))]\]这里的$x$表示原始音频,$s$表示输入的Mel谱图,$z$表示高斯噪声(可不加),$k$表示判别器的尺度。文章还加了特征匹配损失,这一损失除了优化判别器,也优化了生成器,使真实和合成音频的判别器特征图之间的L1距离最小。
\[\mathcal L_{FM}(G,D_k) = \mathbb E_{x,s \sim p_{data}}[\sum_{i=1}^T \frac{1}{N_i}\Vert D_k^{(i)}(x)-D_k^{(i)}(G(s)) \Vert_1]\]其中$D_k^{(i)}$表示第k个判别器的第i层特征图输出,$N_i$表示每层中的单元数,在所有判别块的每个中间层使用特征匹配。最终的生成器的损失可表示如下,其中$\lambda=10$:
\[\min_G ( \mathbb E_{s,z}[\sum_{k=1,2,3} -D_k(G(s,z))] + \lambda \sum_{k=1}^3 \mathcal L_{FM}(G,D_k))\]参数和推断速度:
文章对网络的参数和速度做了对比,如图6所示。
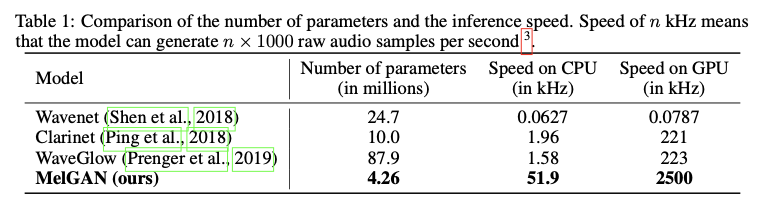
图6.MelGAN参数和速度优势
实验
实验阶段首先是对模型做了消融实验,评判标准是通过人类听力测试评估的音频质量的平均意见得分,得到的结果为图7所示。
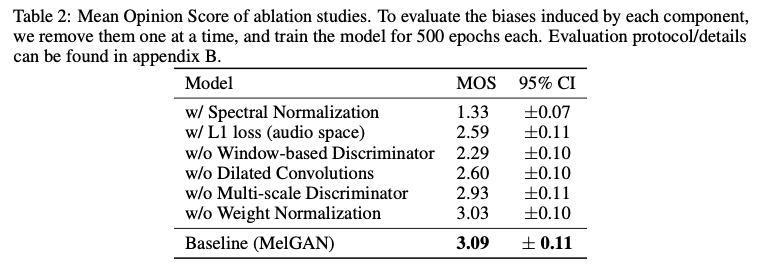
图7.MelGAN消融实验
在文本转语音的实验中,文章将MelGAN与WaveNet、WaveGlow进行了对比,采用的架构如图8所示:

图8.MelGAN实现文本转语音的架构
得到的对比结果如下:

图9.MelGAN在文本转语音上与现有模型对比
可以看出,MelGAN与WaveNet和WaveGlow相当,但是MelGAN速度上的优势还是值得肯定的。
为了证明MelGAN强大并且可以插入自回归模型执行音频生成上,文章用MelGAN取代了Universal Music Translation Network中的WaveNet型自回归解码器。在仅使用目标音乐域中的数据,MelGAN解码器经过训练,可以从潜在编码中重建原始音频。配备MelGAN解码器的音乐翻译网络能够将音乐从任何音乐领域转换到训练有素的目标领域,感兴趣的读者可以在作者公布的Demo上进一步去感受MelGAN的强大。
最后为了进一步确立方法的通用性,作者将VAE中的解码器替换为MelGAN去实现音频的重构,称之为MelGAN VQ-VAE,这一部分已经有学者进行了较好的浮现,代码地址在这里。VQ-VAE的整体架构如图10所示。
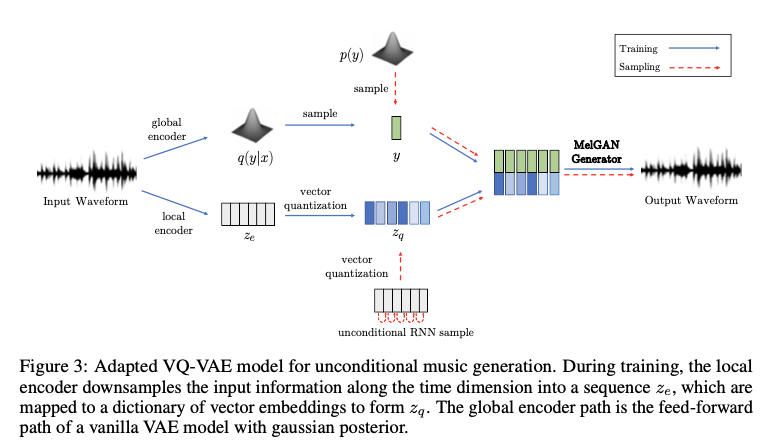
图10.MelGAN取代VAE下的解码器架构设计
总结
MelGAN首次将GAN用于原始音频的生成,这是一个很大的尝试和进步,相信有了这个架构会出现一堆跟进的论文来实现音频的合成。MelGAN能被接受的另一大优势就是它的训练参数和训练时长都是可以接受的,在1080Ti的机子上就可以较好的对论文进行浮现,结合各种语音资料库相信很多学者都可以实现很多有意义的应用。
文章还拓展了MelGAN模型,在无条件下实现了VQ-VAE这种无条件的音频重构,这种重构模型在一定意义上很像是图像翻译下的转换,这一块也将会引领出一些又意义的创新和应用实现,无条件音频生成将很快得到进一步的发展。
参考文献
[1] Van Den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A. W., and Kavukcuoglu, K. Wavenet: A generative model for raw audio. SSW, 125, 2016.
[2] Shen, J., Pang, R., Weiss, R. J., Schuster, M., Jaitly, N., Yang, Z., Chen, Z., Zhang, Y., Wang, Y., Skerrv-Ryan, R., et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)*, pp. 4779–4783. IEEE, 2018.
[3] Griffin, D. and Lim, J. Signal estimation from modified short-time fourier transform. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(2):236–243, 1984.
[4] MORISE, M., YOKOMORI, F., and OZAWA, K. World: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Transactions on Information and Systems, E99.D(7):1877–1884, 2016. doi: 10.1587/transinf.2015EDP7457.
[5] Mehri, S., Kumar, K., Gulrajani, I., Kumar, R., Jain, S., Sotelo, J., Courville, A., and Bengio,Y. Samplernn: An unconditional end-to-end neural audio generation model. arXiv preprint arXiv:1612.07837, 2016.
[6] Kalchbrenner, N., Elsen, E., Simonyan, K., Noury, S., Casagrande, N., Lockhart, E., Stimberg, F., Oord, A. v. d., Dieleman, S., and Kavukcuoglu, K. Efficient neural audio synthesis. arXiv preprint arXiv:1802.08435, 2018.
[7] Oord, A. v. d., Li, Y., Babuschkin, I., Simonyan, K., Vinyals, O., Kavukcuoglu, K., Driessche, G. v. d., Lockhart, E., Cobo, L. C., Stimberg, F., et al. Parallel wavenet: Fast high-fidelity speech synthesis. arXiv preprint arXiv:1711.10433, 2017.
[8] Ping, W., Peng, K., and Chen, J. Clarinet: Parallel wave generation in end-to-end text-to-speech. arXiv preprint arXiv:1807.07281*, 2018.
[9] Prenger, R., Valle, R., and Catanzaro, B. Waveglow: A flow-based generative network for speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3617–3621. IEEE, 2019.
[10] Salimans, T. and Kingma, D. P. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Advances in Neural Information Processing Systems, pp. 901–909, 2016.

感谢您的支持,我会继续努力的!



打开微信扫一扫,即可进行扫码打赏哦







